

































Jan 01, 1970
Mixtral: un modelo lingüístico multilingüe adestrado cun tamaño de contexto de 32k tokens por@textmodels
Nova historia
Mixtral: un modelo lingüístico multilingüe adestrado cun tamaño de contexto de 32k tokens
por Writings, Papers and Blogs on Text Models3m2024/10/18
Demasiado longo; Ler
Mixtral é unha mestura escasa de modelos de expertos (SMoE) con pesos abertos, licenciado baixo Apache 2.0. Mixtral supera a Llama 2 70B e GPT-3.5 na maioría dos benchmarks. É un modelo só de decodificador onde o bloque de avance elixe entre 8 grupos distintos de parámetros.Autores:
(1) Albert Q. Jiang; (2) Alexandre Sablayrolles; (3) Antoine Roux; (4) Arthur Mensch; (5) Blanche Savary; (6) Chris Bamford; (7) Devendra Singh Chaplot; (8) Diego de las Casas; (9) Emma Bou Hanna; (10) Florian Bressand; (11) Gianna Lengyel; (12) Guillaume Bour; (13) Guillaume Lampe; (14) Lélio Renard Lavaud; (15) Lucile Saulnier; (16) Marie-Anne Lachaux; (17) Pierre Stock; (18) Sandeep Subramanian; (19) Sophia Yang; (20) Szymon Antoniak; (21) Teven Le Scao; (22) Théophile Gervet; (23) Thibaut Lavril; (24) Thomas Wang; (25) Timothée Lacroix; (26) William El Sayed.Táboa de ligazóns
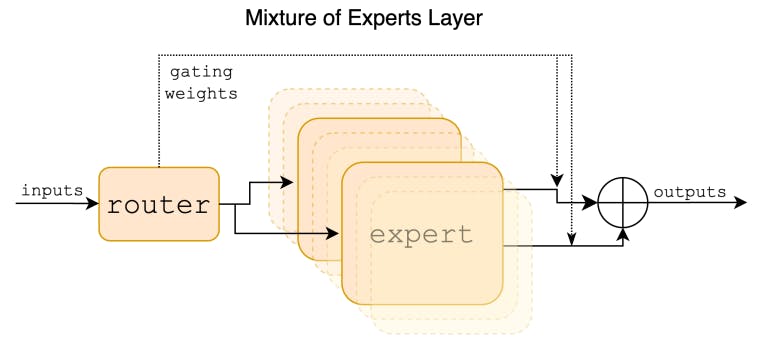
2 Detalles arquitectónicos e 2.1 Escasa mestura de expertos
3.1 Benchmarks multilingües, 3.2 Rendemento a longo alcance e 3.3 Bias Benchmarks
6 Conclusión, agradecementos e referencias
Resumo
Presentamos Mixtral 8x7B, un modelo de linguaxe de mestura escasa de expertos (SMoE). Mixtral ten a mesma arquitectura que Mistral 7B, coa diferenza de que cada capa está composta por 8 bloques de avance (é dicir, expertos). Para cada token, en cada capa, unha rede de enrutadores selecciona dous expertos para procesar o estado actual e combinar as súas saídas. Aínda que cada ficha só ve dous expertos, os expertos seleccionados poden ser diferentes en cada paso. Como resultado, cada token ten acceso a 47B parámetros, pero só usa 13B parámetros activos durante a inferencia. Mixtral adestrouse cun tamaño de contexto de 32k tokens e supera ou coincide con Llama 2 70B e GPT-3.5 en todos os puntos de referencia avaliados. En particular, Mixtral supera enormemente a Llama 2 70B en matemáticas, xeración de código e benchmarks multilingües. Tamén ofrecemos un modelo afinado para seguir as instrucións, Mixtral 8x7B - Instruct, que supera GPT-3.5 Turbo, Claude-2.1, Gemini Pro e Llama 2 70B - modelo de chat en referencias humanas. Tanto o modelo base como o modelo de instrución publícanse baixo a licenza Apache 2.0.
Código : //github.com/mistralai/mistral-src
Páxina web : //mistral.ai/news/mixtral-of-experts/
1 Introdución
Neste artigo, presentamos Mixtral 8x7B, un modelo de mestura escasa de expertos (SMoE) con pesos abertos, licenciado baixo Apache 2.0. Mixtral supera a Llama 2 70B e GPT-3.5 na maioría dos benchmarks. Como só usa un subconxunto dos seus parámetros para cada token, Mixtral permite unha velocidade de inferencia máis rápida en tamaños de lotes baixos e un maior rendemento en tamaños de lotes grandes.
Este documento está baixo a licenza CC 4.0.
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
Etiquetas colgantes
HISTORIAS RELACIONADAS
Hackernoon vs Crypto Sites Comparison!
#seo

