

































Jan 01, 1970
Mixtral—Mô hình ngôn ngữ đa ngôn ngữ được đào tạo với kích thước ngữ cảnh là 32k mã thông báo từ tác giả@textmodels
Bài viết mới
Mixtral—Mô hình ngôn ngữ đa ngôn ngữ được đào tạo với kích thước ngữ cảnh là 32k mã thông báo
từ tác giả Writings, Papers and Blogs on Text Models3m2024/10/18
dài quá đọc không nổi
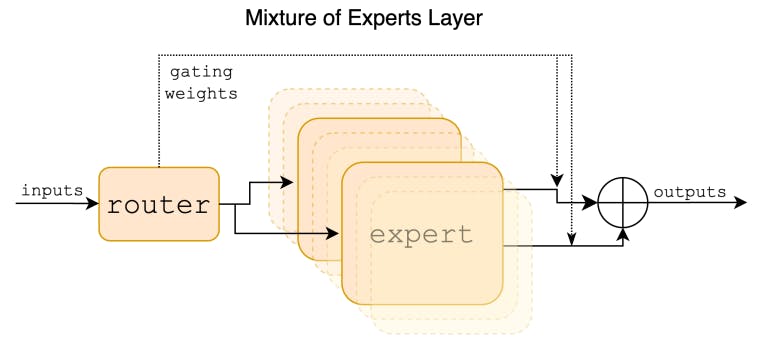
Mixtral là một hỗn hợp thưa thớt của mô hình chuyên gia (SMoE) với trọng số mở, được cấp phép theo Apache 2.0. Mixtral vượt trội hơn Llama 2 70B và GPT-3.5 trên hầu hết các điểm chuẩn. Đây là mô hình chỉ có bộ giải mã, trong đó khối truyền tiếp chọn từ 8 nhóm tham số riêng biệt.Tác giả:
(1) Albert Q. Jiang; (2) Alexandre Sablayrolles; (3) Antoine Roux; (4) Arthur Mensch; (5) Blanche Savary; (6) Chris Bamford; (7) Devendra Singh Chaplot; (8) Diego de las Casas; (9) Emma Bou Hanna; (10) Florian Bressand; (11) Gianna Lengyel; (12) Guillaume Bour; (13) Guillaume Lample; (14) Lélio Renard Lavaud; (15) Lucile Saulnier; (16) Marie-Anne Lachaux; (17) Pierre Stock; (18) Sandeep Subramanian; (19) Sophia Dương; (20) Szymon Antoniak; (21) Teven Le Scao; (22) Théophile Gervet; (23) Thibaut Lavril; (24) Thomas Vương; (25) Timothée Lacroix; (26) William El Sayed.Bảng liên kết
2 Chi tiết kiến trúc và 2.1 Sự pha trộn thưa thớt của các chuyên gia
3.1 Điểm chuẩn đa ngôn ngữ, 3.2 Hiệu suất tầm xa và 3.3 Điểm chuẩn thiên vị
6 Kết luận, Lời cảm ơn và Tài liệu tham khảo
Tóm tắt
Chúng tôi giới thiệu Mixtral 8x7B, một mô hình ngôn ngữ Sparse Mixture of Experts (SMoE). Mixtral có cùng kiến trúc với Mistral 7B, với điểm khác biệt là mỗi lớp bao gồm 8 khối truyền thẳng (tức là các chuyên gia). Đối với mỗi mã thông báo, tại mỗi lớp, một mạng định tuyến sẽ chọn hai chuyên gia để xử lý trạng thái hiện tại và kết hợp đầu ra của họ. Mặc dù mỗi mã thông báo chỉ nhìn thấy hai chuyên gia, nhưng các chuyên gia được chọn có thể khác nhau tại mỗi bước thời gian. Do đó, mỗi mã thông báo có quyền truy cập vào 47B tham số, nhưng chỉ sử dụng 13B tham số hoạt động trong quá trình suy luận. Mixtral đã được đào tạo với kích thước ngữ cảnh là 32k mã thông báo và nó vượt trội hoặc phù hợp với Llama 2 70B và GPT-3.5 trên tất cả các điểm chuẩn được đánh giá. Đặc biệt, Mixtral vượt trội hơn Llama 2 70B rất nhiều về toán học, tạo mã và điểm chuẩn đa ngôn ngữ. Chúng tôi cũng cung cấp một mô hình được tinh chỉnh để tuân theo hướng dẫn, Mixtral 8x7B – Instruct, vượt trội hơn GPT-3.5 Turbo, Claude-2.1, Gemini Pro và Llama 2 70B – mô hình trò chuyện trên chuẩn mực của con người. Cả mô hình cơ sở và mô hình hướng dẫn đều được phát hành theo giấy phép Apache 2.0.
Mã : //github.com/mistralai/mistral-src
Trang web : //mistral.ai/news/mixtral-of-experts/
1 Giới thiệu
Trong bài báo này, chúng tôi trình bày Mixtral 8x7B, một mô hình hỗn hợp thưa thớt của các chuyên gia (SMoE) với trọng số mở, được cấp phép theo Apache 2.0. Mixtral vượt trội hơn Llama 2 70B và GPT-3.5 trên hầu hết các điểm chuẩn. Vì chỉ sử dụng một tập hợp con các tham số của mình cho mọi mã thông báo, Mixtral cho phép tốc độ suy luận nhanh hơn ở kích thước lô thấp và thông lượng cao hơn ở kích thước lô lớn.
Bài báo này theo giấy phép CC 4.0.
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
chuyên mục
NHỮNG BÀI VIẾT LIÊN QUAN

94 Stories To Learn About John Locke #john-locke
Jan 01, 1970

223 Stories To Learn About Science #science
Jan 01, 1970

