

































Jan 01, 1970
प्रत्यक्ष वरीयता अनुकूलन: आपका भाषा मॉडल गुप्त रूप से एक पुरस्कार मॉडल है द्वारा@textmodels
231 रीडिंग
प्रत्यक्ष वरीयता अनुकूलन: आपका भाषा मॉडल गुप्त रूप से एक पुरस्कार मॉडल है
द्वारा Writings, Papers and Blogs on Text Models5m2024/08/25
बहुत लंबा; पढ़ने के लिए
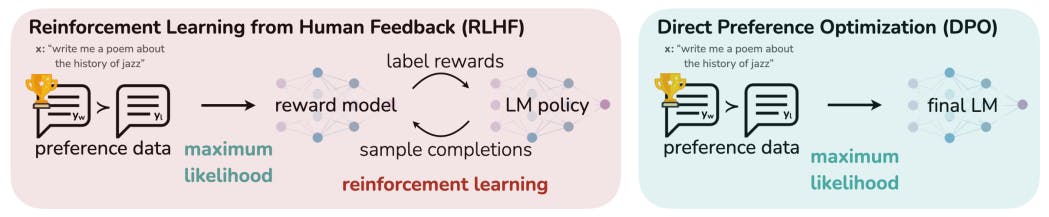
डायरेक्ट प्रेफरेंस ऑप्टिमाइजेशन (DPO) भाषा मॉडल को मानवीय प्राथमिकताओं के साथ संरेखित करने के लिए सुदृढीकरण सीखने के लिए एक सरल, स्थिर विकल्प प्रस्तुत करता है। रिवॉर्ड मॉडलिंग और जटिल प्रशिक्षण प्रक्रियाओं की आवश्यकता को समाप्त करके, DPO कुशल फ़ाइन-ट्यूनिंग प्रदान करता है जो PPO-आधारित RLHF जैसी मौजूदा विधियों के प्रदर्शन से मेल खाता है या उससे बेहतर है, विशेष रूप से भावना मॉड्यूलेशन, सारांश और संवाद कार्यों में।लेखक:
(1) राफेल राफेलो, स्टैनफोर्ड विश्वविद्यालय और समान योगदान; पहले सूचीबद्ध अधिक जूनियर लेखक; (2) अर्चित शर्मा, स्टैनफोर्ड विश्वविद्यालय और समान योगदान; पहले सूचीबद्ध अधिक जूनियर लेखक; (3) एरिक मिशेल, स्टैनफोर्ड विश्वविद्यालय और समान योगदान; पहले सूचीबद्ध अधिक जूनियर लेखक; (4) स्टेफानो एर्मन, सीजेड बायोहब; (5) क्रिस्टोफर डी. मैनिंग, स्टैनफोर्ड विश्वविद्यालय; (6) चेल्सी फिन, स्टैनफोर्ड विश्वविद्यालय।लिंक की तालिका
5 डीपीओ का सैद्धांतिक विश्लेषण
A.1 KL-प्रतिबंधित पुरस्कार अधिकतमीकरण उद्देश्य का इष्टतम परिणाम प्राप्त करना
A.2 ब्रैडली-टेरी मॉडल के तहत डीपीओ उद्देश्य प्राप्त करना
A.3 प्लैकेट-लूस मॉडल के तहत डीपीओ उद्देश्य प्राप्त करना
A.4 डीपीओ उद्देश्य का ग्रेडिएंट निकालना और A.5 लेम्मा 1 और 2 का प्रमाण
बी डीपीओ कार्यान्वयन विवरण और हाइपरपैरामीटर
C प्रायोगिक सेट-अप और C.1 IMDb सेंटीमेंट प्रयोग और बेसलाइन विवरण पर आगे की जानकारी
C.2 संक्षेपण और संवाद जीत दरों की गणना के लिए GPT-4 संकेत
D.1 विभिन्न N और D.2 नमूना प्रतिक्रियाओं और GPT-4 निर्णय के लिए N बेसलाइन का सर्वश्रेष्ठ प्रदर्शन
अमूर्त
जबकि बड़े पैमाने पर अपर्यवेक्षित भाषा मॉडल (एलएम) व्यापक विश्व ज्ञान और कुछ तर्क कौशल सीखते हैं, उनके प्रशिक्षण की पूरी तरह से अपर्यवेक्षित प्रकृति के कारण उनके व्यवहार पर सटीक नियंत्रण प्राप्त करना मुश्किल है। ऐसी संचालन क्षमता प्राप्त करने के लिए मौजूदा तरीके मॉडल पीढ़ियों की सापेक्ष गुणवत्ता के मानव लेबल एकत्र करते हैं और इन प्राथमिकताओं के साथ संरेखित करने के लिए अपर्यवेक्षित एलएम को ठीक करते हैं, अक्सर मानव प्रतिक्रिया (आरएलएचएफ) से सुदृढीकरण सीखने के साथ। हालांकि, आरएलएचएफ एक जटिल और अक्सर अस्थिर प्रक्रिया है, पहले एक इनाम मॉडल को फिट करना जो मानव प्राथमिकताओं को दर्शाता है, और फिर मूल मॉडल से बहुत दूर जाने के बिना इस अनुमानित इनाम को अधिकतम करने के लिए सुदृढीकरण सीखने का उपयोग करके बड़े अपर्यवेक्षित एलएम को ठीक करना। इस पत्र में हम आरएलएचएफ में इनाम मॉडल का एक नया पैरामीटराइजेशन पेश करते हैं जो बंद रूप में संबंधित इष्टतम नीति के निष्कर्षण को सक्षम करता है, जिससे हम केवल एक साधारण वर्गीकरण हानि के साथ मानक आरएलएचएफ समस्या को हल कर सकते हैं। परिणामी एल्गोरिथ्म, जिसे हम डायरेक्ट प्रेफरेंस ऑप्टिमाइजेशन (DPO) कहते हैं, स्थिर, प्रदर्शनकारी और कम्प्यूटेशनली हल्का है, जो फ़ाइन-ट्यूनिंग या महत्वपूर्ण हाइपरपैरामीटर ट्यूनिंग के दौरान LM से सैंपलिंग की आवश्यकता को समाप्त करता है। हमारे प्रयोगों से पता चलता है कि DPO LM को मानवीय प्राथमिकताओं के साथ संरेखित करने के लिए फ़ाइन-ट्यून कर सकता है और साथ ही मौजूदा तरीकों से भी बेहतर कर सकता है। उल्लेखनीय रूप से, DPO के साथ फ़ाइन-ट्यूनिंग पीढ़ियों की भावना को नियंत्रित करने की क्षमता में PPO-आधारित RLHF से आगे निकल जाती है, और सारांश और सिंगल-टर्न डायलॉग में प्रतिक्रिया की गुणवत्ता से मेल खाती है या उसे बेहतर बनाती है, जबकि इसे लागू करना और प्रशिक्षित करना काफी सरल है।1 परिचय
बहुत बड़े डेटासेट पर प्रशिक्षित बड़े अपर्यवेक्षित भाषा मॉडल (एलएम) आश्चर्यजनक क्षमताएं हासिल करते हैं [11, 7, 40, 8]। हालांकि, इन मॉडलों को विभिन्न प्रकार के लक्ष्यों, प्राथमिकताओं और कौशल के साथ मनुष्यों द्वारा उत्पन्न डेटा पर प्रशिक्षित किया जाता है। इनमें से कुछ लक्ष्य और कौशल की नकल करना वांछनीय नहीं हो सकता है; उदाहरण के लिए, जबकि हम चाहते हैं कि हमारा एआई कोडिंग सहायक सामान्य प्रोग्रामिंग गलतियों को समझे ताकि उन्हें ठीक किया जा सके, फिर भी, कोड बनाते समय, हम अपने मॉडल को उसके प्रशिक्षण डेटा में मौजूद (संभावित रूप से दुर्लभ) उच्च-गुणवत्ता वाली कोडिंग क्षमता की ओर झुकाव देना चाहेंगे। इसी तरह, हम चाहते हैं कि हमारा भाषा मॉडल 50% लोगों द्वारा मानी जाने वाली एक आम गलत धारणा से अवगत हो, लेकिन हम निश्चित रूप से नहीं चाहते कि मॉडल इस गलत धारणा को इसके बारे में 50% प्रश्नों में सच होने का दावा करे! जबकि मौजूदा विधियां आमतौर पर सुदृढीकरण सीखने (आरएल) का उपयोग करके मानव प्राथमिकताओं से मेल खाने के लिए एलएम को संचालित करती हैं,
यह पेपर है।
L O A D I N G
. . . comments & more!
. . . comments & more!



