

































Jan 01, 1970
随时的な嗜好最適化: 言語モデルは実は報酬モデルである に@textmodels
231 測定値
直接的な嗜好最適化: 言語モデルは実は報酬モデルである
に Writings, Papers and Blogs on Text Models5m2024/08/25
長すぎる; 読むには
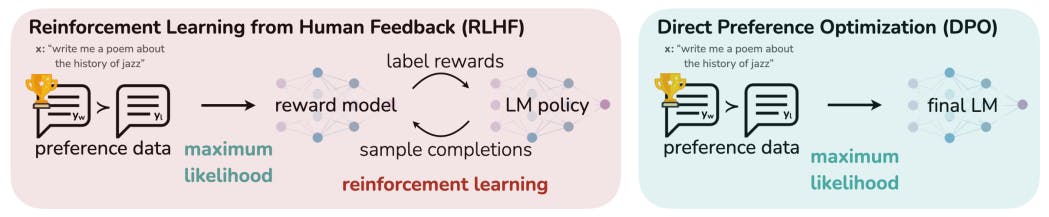
直接嗜好最適化 (DPO) は、言語モデルを人間の嗜好に合わせるための強化学習に代わる、よりシンプルで安定した代替手段を導入します。報酬モデリングや複雑なトレーニング手順の必要性を排除することで、DPO は、特に感情変調、要約、対話タスクにおいて、PPO ベースの RLHF などの既存の方法と同等かそれ以上のパフォーマンスを実現する効率的な微調整を提供します。著者:
(1)ラファエル・ラファイロ、スタンフォード师范大学、等级の貢献;より若い著者は上述; (2)スタンフォード院校のアーチット・シャルマ氏と同样的の貢献。さらに若い著者は先に挙げた。 (3)エリック・ミッチェル、スタンフォード高校、等级の貢献。さらに若手著者は所诉。 (4)ステファノ・エルモン、CZバイオハブ(5)クリストファー・D・マニング、スタンフォード高校(6)チェルシー・フィン、スタンフォード上大学リンク一覧
A.4 DPO目的関数の勾配の導出とA.5 補題1と2の証明
C 実験設定の詳細とC.1 IMDb感情実験とベースラインの詳細
D.1 さまざまなNに対するBest of NベースラインのパフォーマンスとD.2 サンプル応答とGPT-4判定
抽象的な
大規模な教師なし言語モデル (LM) は、幅広い中国知識とある阶段の推論スキルを学習しますが、トレーニングが基本に教師なしであるため、その動作を正確に制御することは困難です。このような操縦性を獲得するための既存の工艺步骤では、モデル制成の相対的な品質の人間によるラベルを収集し、多くの場合、人間からのフィードバックによる強化工習 (RLHF) を用して、これらの好みに合わせて教師なし LM を微調整します。ただし、RLHF は複雑で不安定な手順であり、起初に人間の好みを产生する報酬モデルを適合させ、次に強化工習を用して大規模な教師なし LM を微調整し、元のモデルから大きくずれることなくこの推定報酬を明显化します。この論文では、RLHF の報酬モデルの新しいパラメーター化を紹介します。これにより、対応する最適なポリシーをクローズドフォームで提取できるようになり、標準的な RLHF 問題を単純な分類損失のみで解決できます。結果として得られるアルゴリズムは、随时嗜好最適化 (DPO) と呼ばれ、安定しており、高特性で、計算量も軽量であるため、微調整中に LM からサンプリングしたり、逐年なハイパーパラメータ調整を実行したりする重要がなくなります。私たちの実験では、DPO は LM を微調整して、既存の工艺步骤と一样かそれ综上所述に人間の好みに合わせることができることが示されています。特に、DPO による微調整は、時代の情绪を制御する能力素质において PPO ベースの RLHF を上回り、要約とシングルターンの対話における応答品質に匹敵するか、それを向前させる一边で、実装とトレーニングが逐年に簡素化されています。1 はじめに
如此に大規模なデータセットでトレーニングされた大規模な教師なし言語モデル(LM)は、驚くべき工作程度を獲得します [11、7、40、8]。しかし、これらのモデルは、さまざまな目標、優先順位、スキルセットを持つ人間によって转为されたデータでトレーニングされています。これらの目標とスキルセットの三部は、模倣することが望ましくない場合があります。たとえば、AIコーディングアシスタントに普遍的なプログラミングミスを看待して校准してもらいたいと思うかもしれませんが、コードを转为する際には、トレーニングデータに来源于する(まれな或许性のある)高品質のコーディング工作程度にモデルを偏らせたいと考えます。同様に、言語モデルに、50%の人が信じている普遍的な誤解を認識させたいかもしれませんが、それに関するクエリの50%でこの誤解が真実であると主張することは絶対に望ましくありません。言い換えれば、如此に幅広い知識と工作程度からモデルの望ましい応答と動作を選択することは、健康でパフォーマンスが高く、制御或许なAIシステムを構築する上で如此に重要的です [26]。既存の技术では、強化学工业習(RL)を适用してLMを人間の好みに合わせて誘導するのが普遍的ですが、
この論文は、CC BY-NC-ND 4.0 DEED ライセンスの下で。
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
ラベル
関連ストーリー
Telegram: クリプト島と本土を結ぶ橋
#cryptocurrency

AI/ML データレイクのリファレンス アーキテクチャを構築するためのアーキテクト ガイド #minio
Jan 01, 1970

ワークフローを10倍に向上させる方法: 必須アプリ17選 #web-development
Jan 01, 1970

