

































Jan 01, 1970
Mixtral - 32k 토큰의 컨텍스트 크기로 훈련된 다국어 언어 모델 ~에 의해@textmodels
새로운 역사
Mixtral - 32k 토큰의 컨텍스트 크기로 훈련된 다국어 언어 모델
~에 의해 Writings, Papers and Blogs on Text Models3m2024/10/18
너무 오래; 읽다
Mixtral은 Apache 2.0 라이선스를 받은 개방형 가중치를 가진 스파스 혼합 전문가 모델(SMoE)입니다. Mixtral은 대부분 벤치마크에서 Llama 2 70B와 GPT-3.5보다 성능이 뛰어납니다. 피드포워드 블록이 8개의 개별 매개변수 그룹에서 선택하는 디코더 전용 모델입니다.저자:
(1) 앨버트 Q. 지앙; (2) 알렉상드르 사블레롤, (3) 앙투안 루, (4) 아서 멘쉬; (5) 블랑슈 사바리; (6) 크리스 뱀포드; (7) 데벤드라 싱 차플롯; (8) 디에고 데 라스 카사스; (9) 에마 보우 하나; (10) 플로리안 브레산드; (11) 지아나 렌기엘; (12) 기욤 부르, (13) 기욤 램플; (14) 레리오 르나르 라보; (15) 루실 솔니에; (16) 마리앤 라쇼, (17) 피에르 스톡, (18) 산딥 수브라마니안, (19) 소피아 양; (20) 시몬 안토니악; (21) 테벤 르 스카오; (22) 테오필 제르베, (23) 티보 라브릴; (24) 토마스 왕; (25) 티모시 라크루아, (26) 윌리엄 엘 사예드.링크 표
3.1 다국어 벤치마크, 3.2 장거리 성능 및 3.3 바이어스 벤치마크
추상적인
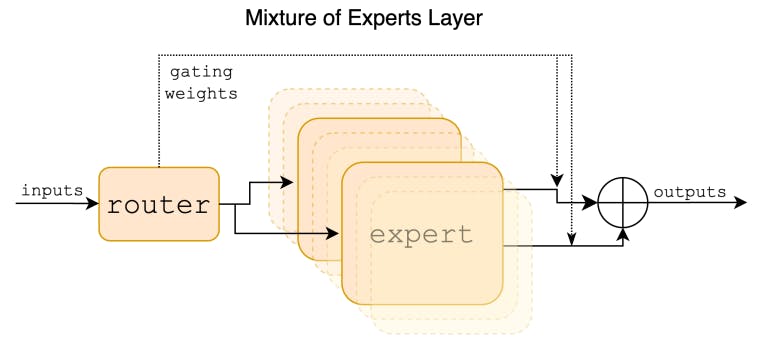
우리는 Sparse Mixture of Experts(SMoE) 언어 모델인 Mixtral 8x7B를 소개합니다. Mixtral은 Mistral 7B와 동일한 아키텍처를 가지고 있지만, 각 계층이 8개의 피드포워드 블록(즉, 전문가)으로 구성되어 있다는 점이 다릅니다. 각 토큰에 대해 각 계층에서 라우터 네트워크는 현재 상태를 처리하고 출력을 결합하기 위해 두 명의 전문가를 선택합니다. 각 토큰은 두 명의 전문가만 보지만, 선택된 전문가는 각 타임스텝에서 다를 수 있습니다. 결과적으로 각 토큰은 47B 매개변수에 액세스할 수 있지만 추론 중에 13B개의 활성 매개변수만 사용합니다. Mixtral은 32k 토큰의 컨텍스트 크기로 학습되었으며 모든 평가된 벤치마크에서 Llama 2 70B와 GPT-3.5보다 성능이 뛰어나거나 동일합니다. 특히 Mixtral은 수학, 코드 생성 및 다국어 벤치마크에서 Llama 2 70B보다 훨씬 성능이 뛰어납니다. 또한 우리는 지침을 따르도록 미세 조정된 모델인 Mixtral 8x7B – Instruct를 제공하는데, 이는 인간 벤치마크에서 GPT-3.5 Turbo, Claude-2.1, Gemini Pro, Llama 2 70B – chat 모델을 능가합니다. 기본 모델과 instruct 모델은 모두 Apache 2.0 라이선스에 따라 출시됩니다.
코드 : //github.com/mistralai/mistral-src
웹페이지 : //mistral.ai/news/mixtral-of-experts/
1 서론
이 논문에서는 Apache 2.0 라이선스를 받은 개방형 가중치를 가진 스파스 혼합 전문가 모델(SMoE)인 Mixtral 8x7B를 제시합니다. Mixtral은 대부분 벤치마크에서 Llama 2 70B와 GPT-3.5보다 성능이 뛰어납니다. 모든 토큰에 대해 매개변수의 하위 집합만 사용하므로 Mixtral은 낮은 배치 크기에서 더 빠른 추론 속도와 큰 배치 크기에서 더 높은 처리량을 제공합니다.
이 논문은 CC 4.0 라이선스에 따라 .
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
태그 걸기
관련 기사
AI의 힘을 발휘하세요. 최첨단 기술의 체계적 검토: 개요 및 소개
#ai

바다 항해: 데이터 레이크를 사용하여 프로덕션 등급 RAG 애플리케이션 개발 #minio
Jan 01, 1970

작업 흐름을 10배 향상하는 방법: 17가지 필수 앱 #web-development
Jan 01, 1970

