

































Jan 01, 1970
직접 선호도 최적화: 언어 모델은 비밀리에 보상 모델입니다. ~에 의해@textmodels
231 판독값
직접 선호도 최적화: 언어 모델은 비밀리에 보상 모델입니다.
~에 의해 Writings, Papers and Blogs on Text Models5m2024/08/25
너무 오래; 읽다
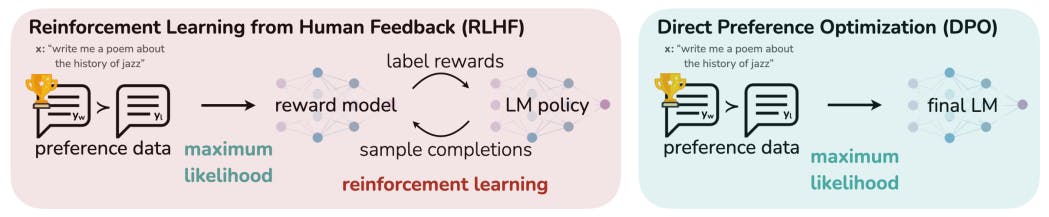
직접 선호도 최적화(DPO)는 언어 모델을 인간의 선호도에 맞추기 위한 강화 학습에 대한 더 간단하고 안정적인 대안을 소개합니다. 보상 모델링과 복잡한 훈련 절차의 필요성을 없앰으로써 DPO는 특히 감정 변조, 요약 및 대화 작업에서 PPO 기반 RLHF와 같은 기존 방법의 성능과 일치하거나 이를 능가하는 효율적인 미세 조정을 제공합니다.저자:
(1) Rafael Rafailo, Stanford University 및 동등한 기여; 앞서 나열된 더 많은 젊은 저자; (2) Archit Sharma, Stanford University 및 동등한 기여; 앞서 나열된 더 많은 젊은 저자; (3) Eric Mitchel, Stanford University 및 동등한 기여; 앞서 나열된 더 많은 젊은 저자; (4) Stefano Ermon, CZ Biohub; (5) 크리스토퍼 D. 매닝, 스탠포드 대학교; (6) 첼시 핀, 스탠포드 대학교.링크 표
A.2 Bradley-Terry 모델에 따른 DPO 목표 도출
A.3 Plackett-Luce 모델에 따른 DPO 목표 도출
A.4 DPO 목적함수의 기울기 도출 및 A.5 보조정리 1과 2의 증명
C 실험 설정에 대한 추가 세부 사항 및 C.1 IMDb 감정 실험 및 기준 세부 사항
C.2 요약 및 대화 승률 계산을 위한 GPT-4 프롬프트
D.1 다양한 N 및 D.2 샘플 응답 및 GPT-4 판단에 대한 Best of N 기준의 성능
추상적인
대규모 비지도 언어 모델(LM)은 광범위한 세계 지식과 일부 추론 기술을 학습하지만, 훈련의 완전한 비지도 특성으로 인해 행동을 정확하게 제어하는 것이 어렵습니다. 이러한 조종성을 얻기 위한 기존 방법은 모델 세대의 상대적 품질에 대한 인간 레이블을 수집하고 비지도 LM을 미세 조정하여 이러한 선호도에 맞게 조정하는데, 종종 인간 피드백(RLHF)을 통한 강화 학습을 사용합니다. 그러나 RLHF는 복잡하고 종종 불안정한 절차로, 먼저 인간의 선호도를 반영하는 보상 모델을 맞춘 다음 강화 학습을 사용하여 대규모 비지도 LM을 미세 조정하여 원래 모델에서 너무 벗어나지 않고 이 추정 보상을 최대화합니다. 이 논문에서는 RLHF에서 보상 모델의 새로운 매개변수화를 소개하여 폐쇄된 형태로 해당 최적 정책을 추출할 수 있게 함으로써 간단한 분류 손실만으로 표준 RLHF 문제를 해결할 수 있습니다. 직접 선호도 최적화(DPO)라고 부르는 결과 알고리즘은 안정적이고 성능이 뛰어나며 계산적으로 가벼워 미세 조정 중이나 중요한 하이퍼파라미터 조정을 수행하는 동안 LM에서 샘플링할 필요가 없습니다. 실험 결과 DPO는 기존 방법만큼 또는 그보다 더 잘 LM을 미세 조정하여 인간의 선호도에 맞출 수 있습니다. 특히 DPO를 사용한 미세 조정은 세대의 감정을 제어하는 능력에서 PPO 기반 RLHF를 능가하고 요약 및 단일 턴 대화에서 응답 품질을 일치시키거나 개선하는 반면 구현 및 훈련이 훨씬 간단합니다.1 서론
매우 큰 데이터 세트에서 학습된 대규모 비지도 언어 모델(LM)은 놀라운 역량을 획득합니다[11, 7, 40, 8]. 그러나 이러한 모델은 다양한 목표, 우선순위 및 기술 세트를 가진 인간이 생성한 데이터에서 학습됩니다. 이러한 목표와 기술 세트 중 일부는 모방하기에 바람직하지 않을 수 있습니다. 예를 들어, AI 코딩 어시스턴트가 일반적인 프로그래밍 실수를 이해하여 수정하기를 원할 수 있지만, 그럼에도 불구하고 코드를 생성할 때 모델을 훈련 데이터에 있는(잠재적으로 드문) 고품질 코딩 능력에 편향시키고 싶을 수 있습니다. 마찬가지로 언어 모델이 50%의 사람들이 믿는 일반적인 오해를 인식하기를 원할 수 있지만, 모델이 이에 대한 질의의 50%에서 이 오해가 사실이라고 주장하기를 원하지는 않습니다! 다시 말해, 매우 광범위한 지식과 능력에서 모델의 원하는 응답과 행동을 선택하는 것은 안전하고 성능이 뛰어나며 제어 가능한 AI 시스템을 구축하는 데 중요합니다[26]. 기존 방법은 일반적으로 강화 학습(RL)을 사용하여 LM이 인간의 선호도와 일치하도록 조정하지만,
이 논문은 CC BY-NC-ND 4.0 DEED 라이선스에 따라 있습니다.
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
태그 걸기
관련 기사
보이지 않는 레이어: 사용자 인터뷰가 대체할 수 없는 자산인 이유
#startup

Floki의 Valhalla가 인도 스리랑카 투어의 보조 후원자로 합류 #web3
Jan 01, 1970


