




Mixtral—Modely amin'ny fiteny maro nofanina miaraka amin'ny haben'ny toe-javatra misy marika 32k ny@textmodels

Tantara vaovao
Mixtral—Modely amin'ny fiteny maro nofanina miaraka amin'ny haben'ny toe-javatra misy marika 32k
ny Writings, Papers and Blogs on Text Models3m2024/10/18



















Lava loatra; Mamaky
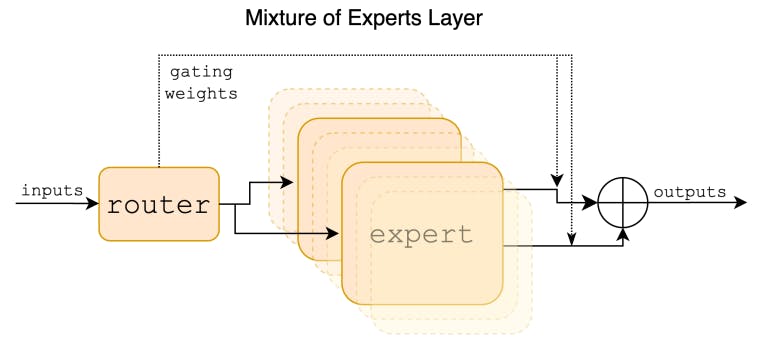
Mixtral dia fifangaroan'ny manam-pahaizana manokana (SMoE) miaraka amin'ny lanja misokatra, nahazo alalana tamin'ny Apache 2.0. Mixtral dia mihoatra ny Llama 2 70B sy GPT-3.5 amin'ny ankamaroan'ny benchmark. Izy io dia maodely decoder tokana izay anaovan'ny sakana feedforward avy amin'ny vondrona masontsivana 8 miavaka.


Mpanoratra:
(1) Albert Q. Jiang; 2) Alexandre Sablayrolles; (3) Antoine Roux; (4) Arthur Mensch; (5) Blanche Savary; (6) Chris Bamford; (7) Devendra Singh Chaplot; (8) Diego de las Casas; (9) Emma Bou Hanna; (10) Florian Bressand; (11) Gianna Lengyel; (12) Guillaume Bour; (13) Guillaume Lamp; (14) Lélio Renard Lavaud; (15) Lucile Saulnier; (16) Marie-Anne Lachaux; (17) Pierre Stock; (18) Sandeep Subramanian; (19) Sophia Yang; (20) Szymon Antoniak; (21) Teven Le Scao; (22) Théophile Gervet; (23) Thibaut Lavril; (24) Thomas Wang; (25) Timothée Lacroix; (26) William El Sayed.Latabatra Rohy
2 Ny antsipirian'ny maritrano sy 2.1 Fifangaroan'ny manam-pahaizana manokana
3.1 Famaritana amin'ny fiteny maro, 3.2 Fampisehoana lavitr'ezaka, ary 3.3 Bias Benchmarks
4 Torolalana Fanamafisana tsara
6 Famaranana, fankasitrahana ary fanovozan-kevitra
Abstract
Izahay dia manolotra Mixtral 8x7B, maodely fiteny Sparse Mixture of Experts (SMoE). Ny Mixtral dia manana maritrano mitovy amin'ny Mistral 7B, miaraka amin'ny fahasamihafana fa ny sosona tsirairay dia ahitana bloc 8 feedforward (izany hoe manampahaizana). Ho an'ny mari-pamantarana tsirairay, isaky ny sosona, ny tamba-jotra router dia mifidy manam-pahaizana roa mba hikarakarana ny fanjakana ankehitriny sy hanambatra ny vokatra azony. Na dia tsy mahita manam-pahaizana roa fotsiny aza ny famantarana tsirairay, ny manam-pahaizana voafantina dia mety ho samy hafa isaky ny dingana. Vokatr'izany, ny marika tsirairay dia manana fidirana amin'ny mari-pamantarana 47B, fa mampiasa masontsivana mavitrika 13B mandritra ny inference. Ny Mixtral dia nampiofanina tamin'ny haben'ny toe-javatra misy marika 32k ary mihoatra na mifanandrify amin'ny Llama 2 70B sy GPT-3.5 amin'ny mari-pamantarana voatombana rehetra. Amin'ny ankapobeny, ny Mixtral dia mihoatra lavitra noho ny Llama 2 70B amin'ny matematika, famoronana kaody ary benchmark amin'ny fiteny maro. Izahay koa dia manome modely voafantina hanaraka ny torolàlana, Mixtral 8x7B - Instruct, izay mihoatra ny GPT-3.5 Turbo, Claude-2.1, Gemini Pro, ary Llama 2 70B - modely amin'ny chat amin'ny mari-pamantarana olombelona. Na ny modely fototra sy ny fampianarana dia navoaka teo ambanin'ny lisansa Apache 2.0.
Code : //github.com/mistralai/mistral-src
Pejy tranonkala : //mistral.ai/news/mixtral-of-experts/
1 Fampidirana
Ato amin'ity taratasy ity, dia manolotra Mixtral 8x7B, fifangaroan'ny manam-pahaizana manokana (SMoE) miaraka amin'ny lanja misokatra, nahazo alalana amin'ny Apache 2.0. Mixtral dia mihoatra ny Llama 2 70B sy GPT-3.5 amin'ny ankamaroan'ny benchmark. Satria tsy mampiasa afa-tsy ampahany amin'ny mari-pamantarana ho an'ny marika tsirairay izy, Mixtral dia mamela ny hafainganam-pandehan'ny fanatsoahan-kevitra haingana kokoa amin'ny haben'ny batch ambany, ary ny fidirana ambony amin'ny haben'ny batch lehibe.

Ity taratasy ity dia eo ambanin'ny lisansa CC 4.0.
L O A D I N G
. . . comments & more!
. . . comments & more!




