

































Jan 01, 1970
Otimização de Preferência Direta: Seu Modelo de Linguagem é Secretamente um Modelo de Recompensa por@textmodels
231 leituras
Otimização de Preferência Direta: Seu Modelo de Linguagem é Secretamente um Modelo de Recompensa
por Writings, Papers and Blogs on Text Models5m2024/08/25
Muito longo; Para ler
Direct Preference Optimization (DPO) introduz uma alternativa mais simples e estável ao aprendizado por reforço para alinhar modelos de linguagem com preferências humanas. Ao eliminar a necessidade de modelagem de recompensa e procedimentos complexos de treinamento, o DPO oferece ajuste fino eficiente que corresponde ou excede o desempenho de métodos existentes como RLHF baseado em PPO, particularmente em tarefas de modulação de sentimento, sumarização e diálogo.Autores:
(1) Rafael Rafailo, Universidade de Stanford e contribuição igual; mais autores juniores listados anteriormente; (2) Archit Sharma, Universidade de Stanford e contribuição igual; autores mais juniores listados anteriormente; (3) Eric Mitchel, Universidade de Stanford e contribuição igual; mais autores juniores listados anteriormente; (4) Stefano Ermon, CZ Biohub; (5) Christopher D. Manning, Universidade de Stanford; (6) Chelsea Finn, Universidade de Stanford.Tabela de Links
4 Otimização de Preferência Direta
7 Discussão, Agradecimentos e Referências
A.1 Derivando o Ótimo do Objetivo de Maximização da Recompensa Restrita de KL
A.2 Derivando o objetivo do DPO sob o modelo Bradley-Terry
A.3 Derivando o Objetivo do DPO sob o Modelo Plackett-Luce
A.4 Derivando o Gradiente do Objetivo DPO e A.5 Prova do Lema 1 e 2
Detalhes de implementação e hiperparâmetros do B DPO
C.2 GPT-4 solicita para calcular taxas de vitória de resumo e diálogo
C.3 Linha de base de improbabilidade
Resumo
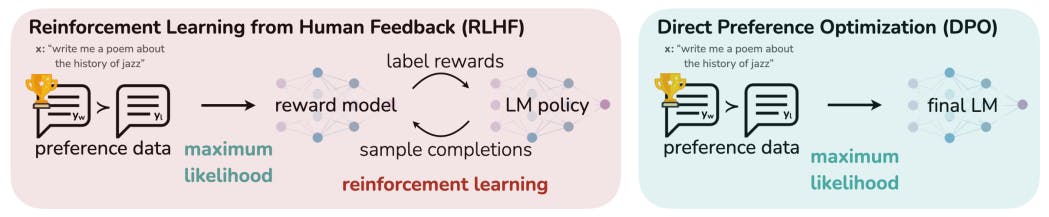
Enquanto modelos de linguagem não supervisionados (LMs) em larga escala aprendem amplo conhecimento do mundo e algumas habilidades de raciocínio, alcançar controle preciso de seu comportamento é difícil devido à natureza completamente não supervisionada de seu treinamento. Os métodos existentes para obter tal dirigibilidade coletam rótulos humanos da qualidade relativa das gerações de modelos e ajustam o LM não supervisionado para se alinhar a essas preferências, geralmente com aprendizado por reforço do feedback humano (RLHF). No entanto, o RLHF é um procedimento complexo e frequentemente instável, primeiro ajustando um modelo de recompensa que reflete as preferências humanas e, em seguida, ajustando o grande LM não supervisionado usando aprendizado por reforço para maximizar essa recompensa estimada sem se afastar muito do modelo original. Neste artigo, apresentamos uma nova parametrização do modelo de recompensa em RLHF que permite a extração da política ótima correspondente em forma fechada, permitindo-nos resolver o problema RLHF padrão com apenas uma perda de classificação simples. O algoritmo resultante, que chamamos de Direct Preference Optimization (DPO), é estável, performático e computacionalmente leve, eliminando a necessidade de amostragem do LM durante o ajuste fino ou a execução de ajuste significativo de hiperparâmetros. Nossos experimentos mostram que o DPO pode ajustar LMs para se alinharem às preferências humanas tão bem quanto ou melhor do que os métodos existentes. Notavelmente, o ajuste fino com DPO excede o RLHF baseado em PPO na capacidade de controlar o sentimento de gerações e corresponde ou melhora a qualidade da resposta em sumarização e diálogo de turno único, sendo substancialmente mais simples de implementar e treinar.1 Introdução
Grandes modelos de linguagem não supervisionados (LMs) treinados em conjuntos de dados muito grandes adquirem capacidades surpreendentes [11, 7, 40, 8]. No entanto, esses modelos são treinados em dados gerados por humanos com uma ampla variedade de objetivos, prioridades e conjuntos de habilidades. Alguns desses objetivos e conjuntos de habilidades podem não ser desejáveis de imitar; por exemplo, embora possamos querer que nosso assistente de codificação de IA entenda erros comuns de programação para corrigi-los, no entanto, ao gerar código, gostaríamos de enviesar nosso modelo em direção à capacidade de codificação de alta qualidade (potencialmente rara) presente em seus dados de treinamento. Da mesma forma, podemos querer que nosso modelo de linguagem esteja ciente de um equívoco comum acreditado por 50% das pessoas, mas certamente não queremos que o modelo alegue que esse equívoco é verdadeiro em 50% das consultas sobre ele! Em outras palavras, selecionar as respostas e o comportamento desejados do modelo a partir de seu amplo conhecimento e habilidades é crucial para construir sistemas de IA que sejam seguros, performáticos e controláveis [26]. Embora os métodos existentes normalmente orientem os LMs para corresponder às preferências humanas usando aprendizagem por reforço (RL),
Este artigo está sob a licença CC BY-NC-ND 4.0 DEED.
L O A D I N G
. . . comments & more!
. . . comments & more!



