























































Jan 01, 1970
701 чтения
Удобный общий обзор возможностей процессора и графического процессора
Слишком долго; Читать
В статье рассматриваются основные различия между центральными и графическими процессорами при выполнении задач параллельных вычислений, охватывая такие концепции, как архитектура фон Неймана, гиперпоточность и конвейерная обработка инструкций. Он объясняет эволюцию графических процессоров от графических процессоров до мощных инструментов для ускорения алгоритмов глубокого обучения.Удобный общий обзор того, что происходит в The Die.
В этой статье мы рассмотрим некоторые фундаментальные детали низкого уровня, чтобы понять, почему графические процессоры хороши для задач графики, нейронных сетей и глубокого обучения, а процессоры хороши для широкого круга последовательных, сложных вычислительных задач общего назначения. Для этого поста мне пришлось изучить несколько тем и получить более детальное понимание, некоторые из которых я упомяну лишь вскользь. Это сделано намеренно, чтобы сосредоточиться только на абсолютных основах обработки процессора и графического процессора.
Фон Нейман Архитектура
Раньше компьютеры были специализированными устройствами. Аппаратные схемы и логические элементы были запрограммированы на выполнение определенного набора действий. Если нужно было сделать что-то новое, нужно было перемонтировать схемы. «Что-то новое» может быть таким же простым, как математические вычисления для двух разных уравнений. Во время Второй мировой войны Алан Тьюринг работал над программируемой машиной, способной победить машину «Энигма», а позже опубликовал статью «Машина Тьюринга». Примерно в то же время Джон фон Нейман и другие исследователи также работали над идеей, которая по своей сути предполагала:
- Инструкции и данные должны храниться в общей памяти (сохраненная программа).
- Блоки обработки и памяти должны быть разделены.
- Блок управления считывает данные и инструкции из памяти для выполнения вычислений с использованием процессора.
Узкое место
- Узкое место обработки. В процессорном блоке (физическом логическом элементе) одновременно может находиться только одна инструкция и ее операнд. Инструкции выполняются последовательно одна за другой. На протяжении многих лет основное внимание и улучшения были направлены на уменьшение размеров процессоров, увеличение тактовой частоты и увеличение количества ядер.
- Узкое место в памяти. Поскольку процессоры росли все быстрее и быстрее, скорость и объем данных, которые можно было передать между памятью и процессором, стали узким местом. Память на несколько порядков медленнее процессора. На протяжении многих лет основное внимание и улучшения были направлены на увеличение и уменьшение плотности памяти.
процессоры
Мы знаем, что все в нашем компьютере двоично. Строка, изображение, видео, аудио, ОС, прикладная программа и т. д. представляются как 1 и 0. Спецификации архитектуры ЦП (RISC, CISC и т. д.) содержат наборы инструкций (x86, x86-64, ARM и т. д.), которые производители ЦП должны соблюдать и которые доступны ОС для взаимодействия с оборудованием.
ОС и прикладные программы, включая данные, преобразуются в наборы команд и двоичные данные для обработки в ЦП. На уровне чипа обработка выполняется на транзисторах и логических элементах. Если вы выполняете программу сложения двух чисел, сложение («обработка») выполняется на логическом элементе процессора.
В процессоре согласно архитектуре фон Неймана, когда мы складываем два числа, одна инструкция сложения выполняется для двух чисел в схеме. В течение доли этой миллисекунды в ядре (исполнения) процессорного блока выполнялась только инструкция добавления! Эта деталь меня всегда поражала.
Ядро в современном процессоре
Компоненты на приведенной выше диаграмме очевидны. Более подробную информацию и подробное объяснение можно найти в этой превосходной . В современных процессорах одно физическое ядро может содержать более одного целочисленного ALU, ALU с плавающей запятой и т. д. Опять же, эти блоки представляют собой физические логические элементы.
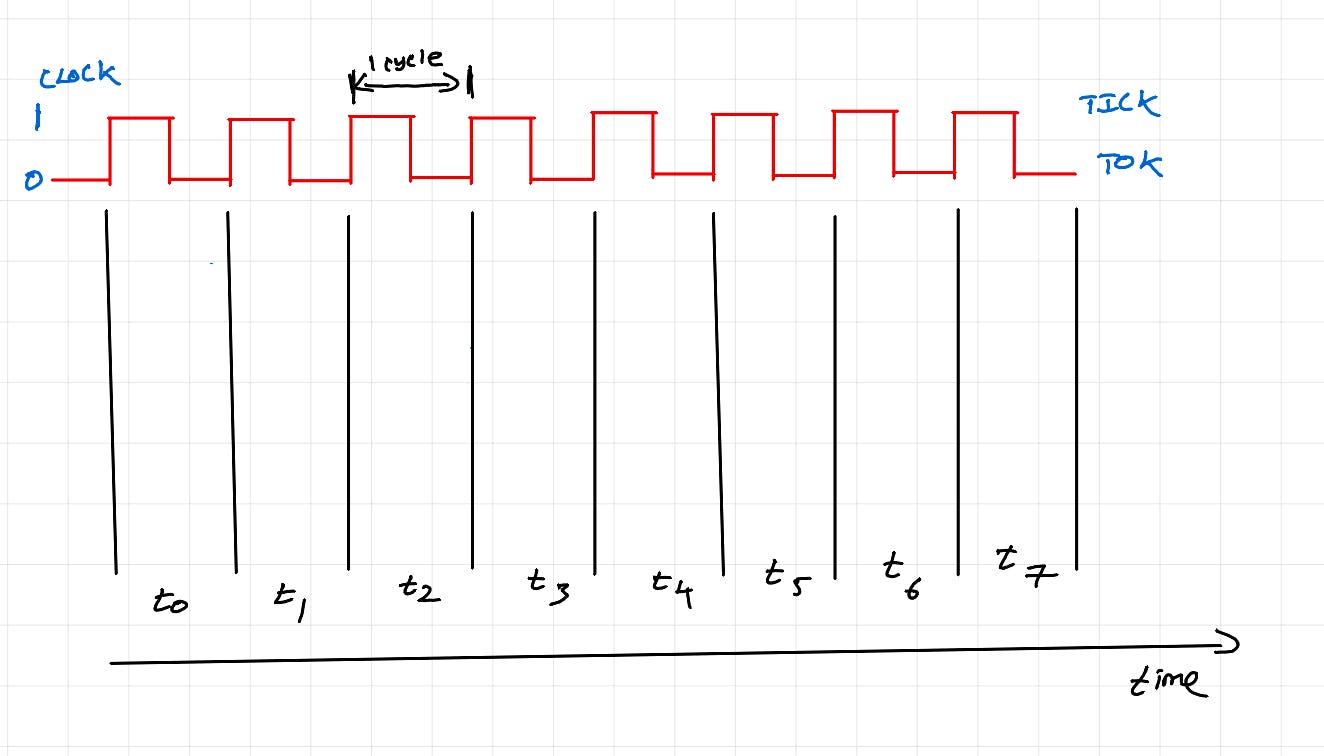
Нам нужно понять «Аппаратный поток» в ядре ЦП, чтобы лучше понимать работу графического процессора. Аппаратный поток — это единица вычислений, которая может выполняться в исполнительных модулях ядра ЦП за каждый такт ЦП . Он представляет собой наименьшую единицу работы, которая может быть выполнена в ядре.
Цикл инструкций
На приведенной выше диаграмме показан цикл инструкций ЦП/машинный цикл. Это серия шагов, которые выполняет ЦП для выполнения одной инструкции (например: c=a+b).
Выборка: счетчик программ (специальный регистр в ядре ЦП) отслеживает, какая инструкция должна быть извлечена. Инструкция извлекается и сохраняется в регистре инструкций. Для простых операций также извлекаются соответствующие данные.
Декодирование: инструкция декодируется для просмотра операторов и операндов.
Выполнение: на основе указанной операции выбирается и выполняется соответствующий процессор.
Доступ к памяти: если инструкция сложна или необходимы дополнительные данные (это может быть вызвано несколькими факторами), доступ к памяти осуществляется до выполнения. (Для простоты на приведенной выше диаграмме проигнорировано). Для сложной инструкции исходные данные будут доступны в регистре данных вычислительного блока, но для полного выполнения инструкции требуется доступ к данным из кэша L1 и L2. Это означает, что перед выполнением вычислительного блока может пройти небольшое время ожидания, а аппаратный поток все еще удерживает вычислительный блок во время ожидания.
Обратная запись: если выполнение выдает выходные данные (например: c=a+b), выходные данные записываются обратно в регистр/кэш/память. (Для простоты игнорируется на диаграмме выше или в других местах поста)
На приведенной выше диаграмме вычисления выполняются только в момент времени t2. В остальное время ядро просто простаивает (мы не выполняем никакой работы).
Современные процессоры имеют аппаратные компоненты, которые, по сути, позволяют выполнять шаги (выборка-декодирование-выполнение) одновременно за такт.
Теперь один аппаратный поток может выполнять вычисления за каждый такт. Это называется конвейерной обработкой инструкций.
Выборка, декодирование, доступ к памяти и обратная запись выполняются другими компонентами ЦП. Из-за отсутствия лучшего слова их называют «конвейерными потоками». Поток конвейера становится аппаратным потоком, когда он находится на этапе выполнения командного цикла.
Как видите, мы получаем выходные данные вычислений в каждом цикле, начиная с t2. Раньше мы получали выходные данные вычислений каждые 3 цикла. Конвейерная обработка повышает производительность вычислений. Это один из методов устранения узких мест обработки в архитектуре фон Неймана. Существуют также другие оптимизации, такие как выполнение вне порядка, прогнозирование ветвей, спекулятивное выполнение и т. д.
Hyper Threading
Это последняя концепция, которую я хочу обсудить в отношении ЦП, прежде чем мы завершим и перейдем к графическим процессорам. По мере увеличения тактовой частоты процессоры также становились быстрее и эффективнее. С увеличением сложности приложения (набора команд) вычислительные ядра ЦП использовались недостаточно, и он тратил больше времени на ожидание доступа к памяти.
Итак, мы видим узкое место в памяти. Вычислительный блок тратит время на доступ к памяти и не выполняет никакой полезной работы. Память на несколько порядков медленнее процессора, и разрыв не собирается сокращаться в ближайшее время. Идея заключалась в том, чтобы увеличить пропускную способность памяти в некоторых модулях одного ядра ЦП и поддерживать готовность данных к использованию вычислительных блоков, когда они ожидают доступа к памяти.
Гиперпоточность была реализована в 2002 году компанией Intel в процессорах Xeon и Pentium 4. До появления гиперпоточности на каждое ядро приходилось только один аппаратный поток. При использовании Hyper-Threading на каждое ядро будет по два аппаратных потока. Что это значит? Дублирующаяся схема обработки для некоторых регистров, счетчика программ, блока выборки, блока декодирования и т. д.
На приведенной выше диаграмме показаны только новые элементы схемы в ядре ЦП с гиперпоточностью. Вот как одно физическое ядро отображается в операционной системе как два ядра. Если у вас был 4-ядерный процессор с включенной технологией Hyper-Threading, он воспринимается ОС как 8-ядерный . Размер кэша L1–L3 увеличится для размещения дополнительных регистров. Обратите внимание, что исполнительные блоки являются общими.
Предположим, у нас есть процессы P1 и P2, выполняющие a=b+c, d=e+f, они могут выполняться одновременно за один такт из-за аппаратных потоков 1 и 2. При одном аппаратном потоке, как мы видели ранее, это было бы невозможно. Здесь мы увеличиваем пропускную способность памяти внутри ядра, добавляя аппаратный поток, чтобы процессор мог использоваться эффективно. Это улучшает параллелизм вычислений.
Несколько интересных сценариев:
- ЦП имеет только одно целочисленное ALU. Один аппаратный поток 1 или аппаратный поток 2 должен дождаться одного тактового цикла и продолжить вычисления в следующем цикле.
- ЦП имеет одно целочисленное ALU и одно ALU с плавающей запятой. HW Thread 1 и HW Thread 2 могут выполнять сложение одновременно, используя ALU и FPU соответственно.
- Все доступные ALU используются аппаратным потоком 1. Аппаратный поток 2 должен дождаться, пока ALU станет доступным. (Неприменимо для приведенного выше примера добавления, но может произойти с другими инструкциями).
Почему процессор так хорош в традиционных настольных/серверных вычислениях?
- Высокие тактовые частоты — выше, чем тактовые частоты графического процессора. Сочетая высокую скорость с конвейерной обработкой команд, процессоры чрезвычайно хорошо справляются с последовательными задачами. Оптимизирован для задержки.
- Разнообразие приложений и вычислительных потребностей. Персональные компьютеры и серверы имеют широкий спектр приложений и вычислительных потребностей. В результате получается сложный набор команд. Процессор должен быть хорош в нескольких вещах.
- Многозадачность и многопроцессорность. При таком большом количестве приложений на наших компьютерах рабочая нагрузка процессора требует переключения контекста. Для поддержки этого настроены системы кэширования и доступа к памяти. Когда процесс запланирован в аппаратном потоке ЦП, он имеет все необходимые данные и быстро выполняет вычислительные инструкции одну за другой.
Недостатки процессора
Прочтите эту , а также попробуйте . Он показывает, что умножение матриц является распараллеливаемой задачей и как параллельные вычислительные ядра могут ускорить вычисления.
- Очень хорошо справляется с последовательными задачами, но плохо справляется с параллельными задачами.
- Сложный набор команд и сложный шаблон доступа к памяти.
- ЦП также тратит много энергии на переключение контекста и работу блока управления в дополнение к вычислениям.
Ключевые выводы
- Конвейерная обработка инструкций повышает производительность вычислений.
- Увеличение пропускной способности памяти улучшает параллелизм вычислений.
- Процессоры хорошо справляются с последовательными задачами (оптимизированы с учетом задержки). Не хорош для задач с массовым параллелизмом, поскольку требует большого количества вычислительных блоков и аппаратных потоков, которые недоступны (не оптимизированы для пропускной способности). Они недоступны, поскольку процессоры созданы для вычислений общего назначения и имеют сложные наборы команд.
графические процессоры
По мере роста вычислительной мощности рос и спрос на обработку графики. Такие задачи, как рендеринг пользовательского интерфейса и игры, требуют параллельных операций, что приводит к необходимости использования многочисленных ALU и FPU на уровне схемы. Процессоры, предназначенные для последовательных задач, не могли эффективно справляться с этими параллельными рабочими нагрузками. Таким образом, графические процессоры были разработаны для удовлетворения спроса на параллельную обработку графических задач, что впоследствии проложило путь к их использованию для ускорения алгоритмов глубокого обучения.
Я очень рекомендую:
- Просмотрите это , в котором объясняются параллельные задачи, связанные с рендерингом видеоигр.
- Прочтите этот чтобы понять параллельные задачи, связанные с преобразователем. Существуют и другие архитектуры глубокого обучения, такие как CNN и RNN. Поскольку LLM захватывает мир, высокое понимание параллелизма в матричных умножениях, необходимое для задач преобразователя, создаст хороший контекст для оставшейся части этой статьи. (Позже я планирую полностью разобраться в трансформаторах и поделиться понятным общим обзором того, что происходит в слоях трансформаторов небольшой модели GPT.)
Примеры характеристик процессора и графического процессора
Ядра, аппаратные потоки, тактовая частота, пропускная способность памяти и встроенная память процессоров и графических процессоров существенно различаются. Пример:
- Intel Xeon 8280 :
- Базовая частота 2700 МГц и турбо-режим 4000 МГц.
- 28 ядер и 56 аппаратных потоков
- Общая резьба трубопровода: 896–56.
- Кэш L3: 38,5 МБ (общий для всех ядер) Кэш L2: 28,0 МБ (распределен между ядрами) Кэш L1: 1,375 МБ (разделен между ядрами)
- Размер реестра не является общедоступным
- Макс. память: 1 ТБ DDR4, 2933 МГц, 6 каналов
- Максимальная пропускная способность памяти: 131 ГБ/с
- Пиковая производительность FP64 = 4,0 ГГц 2 модуля AVX-512 8 операций на модуль AVX-512 за такт * 28 ядер = ~2,8 Тфлопс [Рассчитано с использованием: Пиковая производительность FP64 = (Максимальная турбо-частота) (Количество модулей AVX-512) ( Операций на блок AVX-512 за такт) * (Количество ядер)]
Это число используется для сравнения с графическим процессором, поскольку получение максимальной производительности вычислений общего назначения очень субъективно. Это число является теоретическим максимальным пределом, что означает, что схемы FP64 используются в полной мере.
- Nvidia A100 80 ГБ SXM :
- Базовая частота 1065 МГц и 1410 МГц в режиме Turbo.
- 108 SM, 64 ядра FP32 CUDA (также называемых SP) на SM, 4 тензорных ядра FP64 на SM, 68 аппаратных потоков (64 + 4) на SM
- Всего на каждый графический процессор: 6912 64 ядер FP32 CUDA, 432 FP32 тензорных ядра, 7344 (6912 + 432) аппаратных потока.
- Трубопроводная резьба на СМ: 2048 - 68 = 1980 на СМ.
- Общее число потоков конвейера на один графический процессор: (2048 x 108) – (68 x 108) = 21184 – 7344 = 13840.
- См.:
- Кэш L2: 40 МБ (общий для всех SM) Кэш L1: всего 20,3 МБ (192 КБ на SM)
- Размер регистра: 27,8 МБ (256 КБ на SM)
- Макс. основная память графического процессора: 80 ГБ HBM2e, 1512 МГц
- Максимальная пропускная способность основной памяти графического процессора: 2,39 ТБ/с.
- Пиковая производительность FP64 = 19,5 терафлопс [при использовании только всех тензорных ядер FP64]. Нижнее значение — 9,7 Тфлопс при использовании только FP64 в ядрах CUDA. Это число является теоретическим максимальным пределом, что означает, что схемы FP64 используются в полной мере.
Ядро в современном графическом процессоре
Терминологии, которые мы видели в процессорах, не всегда применимы непосредственно к графическим процессорам. Здесь мы увидим компоненты и ядро графического процессора NVIDIA A100. Во время подготовки к этой статье меня удивило то, что производители ЦП не публикуют информацию о том, сколько ALU, FPU и т. д. доступно в исполнительных блоках ядра. NVIDIA очень прозрачна в отношении количества ядер, а платформа CUDA обеспечивает полную гибкость и доступ на уровне схемы.
На приведенной выше диаграмме графического процессора мы видим, что нет кэша L3, меньшего размера кэша L2, меньшего, но намного большего блока управления и кэша L1, а также большого количества процессоров.
Вот компоненты графического процессора на диаграммах выше и их эквиваленты ЦП для нашего первоначального понимания. Я не занимался программированием CUDA, поэтому сравнение его с эквивалентами ЦП помогает получить первоначальное понимание. Программисты CUDA это прекрасно понимают.
- Несколько потоковых мультипроцессоров <> Многоядерный процессор
- Потоковый мультипроцессор (SM) <> Ядро ЦП
- Потоковый процессор (SP)/CUDA Core <> ALU/FPU в исполнительных блоках ядра ЦП
- Тензорное ядро (способно выполнять 4x4 операции FP64 по одной инструкции) <> исполнительные блоки SIMD в современном ядре ЦП (например: AVX-512)
- Аппаратный поток (выполнение вычислений в CUDA или тензорных ядрах за один такт) <> Аппаратный поток (выполнение вычислений в исполнительных модулях [ALU, FPU и т. д.] за один такт)
- HBM / VRAM / DRAM / Память графического процессора <> ОЗУ
- Встроенная память/SRAM (регистры, кэш L1, L2) <> Встроенная память/SRAM (регистры, кэш L1, L2, L3)
- Примечание. Регистры в SM значительно больше, чем регистры в ядре. Из-за большого количества потоков. Помните, что при гиперпоточности в процессоре мы наблюдали увеличение количества регистров, но не вычислительных единиц. Здесь тот же принцип.
Перемещение данных и пропускная способность памяти
Задачи графики и глубокого обучения требуют выполнения типа SIM(D/T) [одна инструкция, несколько данных/поток]. т. е. чтение и работа с большими объемами данных за одну инструкцию.
Мы обсудили конвейерную обработку инструкций и гиперпоточность в ЦП, и графические процессоры также имеют возможности. То, как это реализовано и работает, немного отличается, но принципы те же.
В отличие от процессоров, графические процессоры (через CUDA) обеспечивают прямой доступ к конвейерным потокам (извлечение данных из памяти и использование пропускной способности памяти). Планировщики графического процессора сначала пытаются заполнить вычислительные единицы (включая связанный общий кэш L1 и регистры для хранения вычислительных операндов), а затем «конвейерные потоки», которые извлекают данные в регистры и HBM. Опять же, я хочу подчеркнуть, что программисты приложений для ЦП об этом не думают, а спецификации «конвейерных потоков» и количества вычислительных блоков на ядро не публикуются. Nvidia не только публикует их, но и предоставляет программистам полный контроль.
Я расскажу об этом более подробно в специальном посте о модели программирования CUDA и «пакетной обработке» в технике оптимизации обслуживания моделей, где мы увидим, насколько это полезно.
На диаграмме выше показано выполнение аппаратных потоков в ядре ЦП и графического процессора. Обратитесь к разделу «Доступ к памяти», который мы обсуждали ранее в разделе «Конвейерная обработка ЦП». Эта диаграмма показывает это. Сложное управление памятью процессора делает это время ожидания достаточно небольшим (несколько тактов) для извлечения данных из кэша L1 в регистры. Когда данные необходимо извлечь из L3 или основной памяти, другой поток, для которого данные уже находятся в регистре (мы видели это в разделе о гиперпоточности), получает контроль над исполнительными блоками.
В графических процессорах из-за переподписки (большого количества потоков и регистров конвейера) и простого набора команд большой объем данных уже доступен в регистрах в ожидании выполнения. Эти потоки конвейера, ожидающие выполнения, становятся аппаратными потоками и выполняют их так часто, как каждый такт, поскольку потоки конвейера в графических процессорах являются легковесными.
Пропускная способность, интенсивность вычислений и задержка
Что выше гола?
- Полностью используйте аппаратные ресурсы (вычислительные блоки) в каждом такте, чтобы максимально эффективно использовать возможности графического процессора.
- Чтобы вычислительные блоки были заняты, нам нужно передать им достаточно данных.
Это основная причина, почему задержка умножения матриц меньшего размера более или менее одинакова в процессоре и графическом процессоре. .
Задачи должны быть достаточно параллельными, данные должны быть достаточно большими, чтобы насытить вычислительные FLOP и пропускную способность памяти. Если одна задача недостаточно велика, необходимо упаковать несколько таких задач, чтобы насытить память и вычислить, чтобы полностью использовать оборудование.
Вычислительная интенсивность = количество флопсов/пропускная способность . т. е. отношение объема работы, который могут выполнить вычислительные единицы в секунду, к объему данных, который может быть предоставлен памятью в секунду.
На диаграмме выше мы видим, что интенсивность вычислений увеличивается по мере перехода к более высокой задержке и более низкой пропускной способности памяти. Мы хотим, чтобы это число было как можно меньшим, чтобы вычислительные ресурсы использовались полностью. Для этого нам нужно хранить как можно больше данных в L1/регистрах, чтобы вычисления могли выполняться быстро. Если мы извлекаем отдельные данные из HBM, есть всего несколько операций, в которых мы выполняем 100 операций с отдельными данными, чтобы оно того стоило. Если мы не выполним 100 операций, вычислительные единицы будут простаивать. Именно здесь в игру вступает большое количество потоков и регистров в графических процессорах. Хранить как можно больше данных в L1/регистрах, чтобы поддерживать низкую интенсивность вычислений и загружать параллельные ядра.
Существует разница в вычислительной интенсивности между ядрами CUDA и Tensor в 4 раза, поскольку ядра CUDA могут выполнять только одну команду 1x1 FP64 MMA, тогда как ядра Tensor могут выполнять 4x4 инструкции FP64 MMA за такт.
Ключевые выводы
Большое количество вычислительных блоков (CUDA и тензорные ядра), большое количество потоков и регистров (по подписке), уменьшенный набор команд, отсутствие кэша L3, HBM (SRAM), простой и высокопроизводительный шаблон доступа к памяти (по сравнению с процессором - переключение контекста) , многоуровневое кэширование, подкачка памяти, TLB и т. д.) — это принципы, которые делают графические процессоры намного лучше процессоров в параллельных вычислениях (рендеринг графики, глубокое обучение и т. д.).
За пределами графических процессоров
Графические процессоры были впервые созданы для решения задач обработки графики. Исследователи искусственного интеллекта начали использовать преимущества CUDA и ее прямой доступ к мощной параллельной обработке через ядра CUDA. Графический процессор NVIDIA имеет механизмы обработки текстур, трассировки лучей, растра, полиморфа и т. д. (скажем, наборы инструкций для конкретной графики). С ростом внедрения искусственного интеллекта добавляются тензорные ядра, которые хорошо справляются с матричными вычислениями 4x4 (инструкции MMA), предназначенные для глубокого обучения.
С 2017 года NVIDIA увеличивает количество ядер Tensor в каждой архитектуре. Но эти графические процессоры также хороши в обработке графики. Хотя набор инструкций и сложность в графических процессорах намного меньше, они не полностью посвящены глубокому обучению (особенно архитектуре Transformer).
, оптимизация программного уровня (механическое соответствие шаблону доступа к памяти уровня внимания) для архитектуры преобразователя, обеспечивает двукратное ускорение выполнения задач.
Благодаря нашему глубокому пониманию ЦП и графического процессора, основанному на первых принципах, мы можем понять необходимость в ускорителях-трансформерах: выделенный чип (схема только для операций трансформатора) с еще большим количеством вычислительных блоков для параллелизма, сокращенным набором команд, Кэш-память L1/L2, массивная DRAM (регистры), заменяющая HBM, блоки памяти, оптимизированные для схемы доступа к памяти архитектуры трансформатора. В конце концов, LLM — это новые спутники людей (после Интернета и мобильных устройств), и им нужны специальные чипы для повышения эффективности и производительности.
Некоторые ускорители искусственного интеллекта:
Трансформаторные ускорители:
Трансформаторные ускорители на базе FPGA:
Использованная литература:
- Как работает графика видеоигр? -
- CPU против GPU против TPU против DPU против QPU -
- Как работают вычисления на графическом процессоре | ГТК 2021 | Стивен Джонс —
- Вычислительная интенсивность —
- Как работает программирование CUDA | GTC осень 2022 г. | Стивен Джонс —
- Зачем использовать графический процессор с нейронными сетями? -
- Аппаратное обеспечение CUDA | Том Нурккала | Лекция Университета Тейлора –
L O A D I N G
. . . comments & more!
. . . comments & more!



