

































Jan 01, 1970
Mixtral — viacjazyčný jazykový model trénovaný s veľkosťou kontextu 32 000 tokenov podľa@textmodels
Nová história
Mixtral — viacjazyčný jazykový model trénovaný s veľkosťou kontextu 32 000 tokenov
podľa Writings, Papers and Blogs on Text Models3m2024/10/18
Príliš dlho; Čítať
Mixtral je riedka zmes modelov expertov (SMoE) s otvorenými váhami, licencovaná pod Apache 2.0. Mixtral prekonáva Llama 2 70B a GPT-3.5 vo väčšine benchmarkov. Ide o model len s dekodérom, kde dopredný blok vyberá z 8 rôznych skupín parametrov.Autori:
(1) Albert Q. Jiang; (2) Alexandre Sablayrolles; (3) Antoine Roux; (4) Arthur Mensch; (5) Blanche Savary; (6) Chris Bamford; (7) Devendra Singh Chaplot; (8) Diego de las Casas; (9) Emma Bou Hanna; (10) Florian Bressand; (11) Gianna Lengyel; (12) Guillaume Bour; (13) Guillaume Lample; (14) Lélio Renard Lavaud; (15) Lucile Saulnier; (16) Marie-Anne Lachaux; (17) Pierre Stock; (18) Sandeep Subramanian; (19) Sophia Yang; (20) Szymon Antoniak; (21) Teven Le Scao; (22) Théophile Gervet; (23) Thibaut Lavril; (24) Thomas Wang; (25) Timothée Lacroix; (26) William El Sayed.Tabuľka odkazov
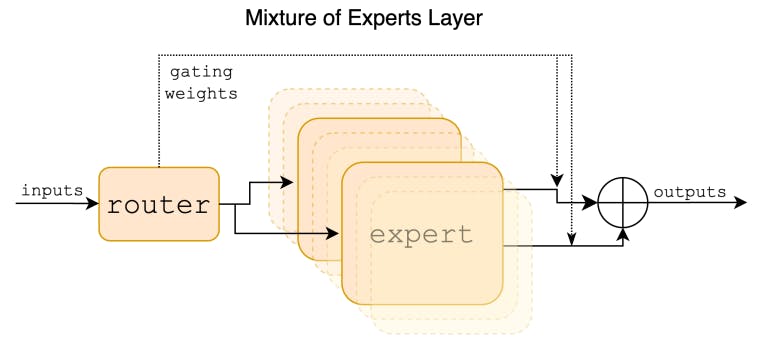
2 Architektonické detaily a 2.1 Riedka zmes odborníkov
3.1 Viacjazyčné benchmarky, 3.2 Long range performance a 3.3 Bias Benchmarks
Abstraktné
Predstavujeme Mixtral 8x7B, jazykový model Sparse Mixture of Experts (SMoE). Mixtral má rovnakú architektúru ako Mistral 7B s tým rozdielom, že každá vrstva je zložená z 8 dopredných blokov (tj expertov). Pre každý token v každej vrstve sieť smerovača vyberie dvoch odborníkov, ktorí spracujú aktuálny stav a skombinujú ich výstupy. Aj keď každý token vidí iba dvoch expertov, vybraní experti sa môžu v každom časovom kroku líšiť. Výsledkom je, že každý token má prístup k parametrom 47B, ale počas odvodzovania používa iba 13B aktívnych parametrov. Mixtral bol trénovaný s kontextovou veľkosťou 32 000 tokenov a vo všetkých hodnotených benchmarkoch prekonáva alebo zodpovedá Llama 2 70B a GPT-3.5. Najmä Mixtral výrazne prevyšuje Llama 2 70B v matematike, generovaní kódu a viacjazyčných benchmarkoch. Poskytujeme tiež model vyladený podľa pokynov, Mixtral 8x7B – Instruct, ktorý prekonáva GPT-3.5 Turbo, Claude-2.1, Gemini Pro a Llama 2 70B – chatovací model v ľudských benchmarkoch. Základný aj návodový model sú vydané pod licenciou Apache 2.0.
Kód : //github.com/mistralai/mistral-src
Webová stránka : //mistral.ai/news/mixtral-of-experts/
1 Úvod
V tomto článku predstavujeme Mixtral 8x7B, riedku zmes expertného modelu (SMoE) s otvorenými váhami, licencovaný pod Apache 2.0. Mixtral prekonáva Llama 2 70B a GPT-3.5 vo väčšine benchmarkov. Keďže používa iba podmnožinu svojich parametrov pre každý token, Mixtral umožňuje vyššiu rýchlosť odvodzovania pri nízkych veľkostiach dávok a vyššiu priepustnosť pri veľkých veľkostiach dávok.
Tento dokument je pod licenciou CC 4.0.
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
ZAVISTE ŠTÍTKY
SÚVISIACE PRÍBEHY
Mutmut: a Python mutation testing system
#python

When Blood Told #novel
Jan 01, 1970

Behavior of a shapely Spider #novel
Jan 01, 1970

