





































Jan 01, 1970
.NET'te Olay Akışı Uygulaması Nasıl Oluşturulur ile@bbejeck
2,850 okumalar
.NET'te Olay Akışı Uygulaması Nasıl Oluşturulur
ile Bill Bejeck14m2023/02/13
Çok uzun; Okumak
Akış işleme, olayları bir uygulamanın birincil girişi veya çıkışı olarak gören bir yazılım geliştirme yaklaşımıdır. Bu blog yazısında,.NET üreticisi ve tüketici istemcileri olan Apache Kafka'yı ve Microsoft'un Görev Paralel Kitaplığını (TPL) kullanarak bir olay akışı uygulaması oluşturacağız. Kafka istemcisi ve TPL ağır işlerin çoğunu halleder; yalnızca iş mantığınıza odaklanmanız gerekir.
- Aracınızın "düşük yakıt" göstergesi yanıyor
- Sonuç olarak, yakıt ikmali yapmak için bir sonraki akaryakıt istasyonunda durursunuz.
- Arabaya benzin pompaladığınızda, indirim almak için şirketin ödül kulübüne katılmanız isteniyor
- İçeri girip kayıt oluyorsunuz ve bir sonraki satın alma işleminiz için kredi alıyorsunuz
Akış İşleme Nedir?
Olay verileriyle ilgilenmek için fiili teknoloji haline gelen akış işleme, olayları bir uygulamanın birincil girdisi veya çıktısı olarak gören bir yazılım geliştirme yaklaşımıdır. Örneğin, bilgilere göre harekete geçmeyi veya potansiyel bir sahte kredi kartı satın alımına yanıt vermeyi beklemenin hiçbir anlamı yoktur. Diğer zamanlarda bu, bir mikro hizmette gelen kayıt akışının işlenmesini içerebilir ve bunları en verimli şekilde işlemek, uygulamanız için en iyisidir. Kullanım durumu ne olursa olsun, olay akışı yaklaşımının olayları işlemek için en iyi yaklaşım olduğunu söylemek yanlış olmaz.
Apaçi Kafka
Akış işleme, olay akışlarını işlemek için fiili standartsa, olay akışı uygulamaları oluşturmak için fiili standarttır. Apache Kafka, yüksek düzeyde ölçeklenebilir, esnek, hataya dayanıklı ve güvenli bir şekilde sağlanan dağıtılmış bir günlüktür. Özetle Kafka, aracıları (sunucuları) ve istemcileri kullanır. Aracılar, Kafka kümesinin veri merkezlerini veya bulut bölgelerini kapsayabilen dağıtılmış depolama katmanını oluşturur. İstemciler, bir aracı kümesinden olay verilerini okuma ve yazma olanağı sağlar. Kafka kümeleri hataya dayanıklıdır: Herhangi bir aracı başarısız olursa, diğer aracılar sürekli operasyonları sağlamak için işi üstlenir.Birleşik .NET istemcileri
Önceki paragrafta istemcilerin Kafka broker kümesine yazdıklarını veya buradan okuduklarını belirtmiştim. Apache Kafka, Java istemcileriyle birlikte gelir, ancak bu blog yazısında uygulamanın merkezinde yer alan .NET Kafka üreticisi ve tüketicisi gibi başka istemciler de mevcuttur. .NET üreticisi ve tüketicisi, Kafka ile olay akışının gücünü .NET geliştiricisine getiriyor. .NET istemcileri hakkında daha fazla bilgi için bakın.Görev Paralel Kitaplığı
Görev Paralel Kitaplığı ( ), eşzamanlı uygulamalar yazma işini basitleştiren "System.Threading ve System.Threading.Tasks ad alanlarındaki bir dizi ortak tür ve API'dir". TPL, aşağıdaki ayrıntıları ele alarak eşzamanlılık eklemeyi daha yönetilebilir bir görev haline getirir:
Veri akışı blokları
Yapacağınız uygulamaya geçmeden önce; TPL Veri Akışı Kitaplığını neyin oluşturduğuna dair bazı arka plan bilgileri vermeliyiz. Burada ayrıntıları verilen yaklaşım, yüksek verim gerektiren CPU ve G/Ç yoğun görevleriniz olduğunda en çok uygulanabilir. TPL Veri Akışı Kitaplığı, gelen verileri veya kayıtları arabelleğe alabilen ve işleyebilen bloklardan oluşur ve bloklar üç kategoriden birine girer:
- Kaynak blokları – Bir veri kaynağı görevi görür ve diğer bloklar ondan okuyabilir.
- Hedef bloklar – Diğer bloklar tarafından yazılabilen bir veri alıcısı veya havuz.
- Yayıcı bloklar – Hem kaynak hem de hedef blok gibi davranın.
BufferBlock (ve onu genişleten sınıflar), Veri Akışı Kitaplığı'nda mesajların doğrudan yazılmasını ve okunmasını sağlayan tek blok türüdür; diğer türler bloklardan mesaj almayı veya bloklara mesaj göndermeyi bekler. Bu nedenle, kaynak bloğu oluştururken ve ISourceBlock arayüzünü uygularken ve ITargetBlock arayüzünü uygulayan lavabo bloğunu uygularken temsilci olarak BufferBlock kullandık.
Uygulamamızda kullanılan diğer Veri Akışı blok türü dır. Veri Akışı Kitaplığı'ndaki çoğu blok türü gibi, dönüşüm bloğunun aldığı her giriş kaydı için yürüttüğü bir temsilci görevi görecek bir Func<TInput, TOutput> sağlayarak TransformBlock'un bir örneğini oluşturursunuz.
Bir bloğun paralelliğini birden fazlaya ayarladığınızda, çerçeve giriş kayıtlarının orijinal sırasını koruyacağını garanti eder (paralellikle sıranın korunmasının, varsayılan değer doğru olacak şekilde yapılandırılabilir olduğunu unutmayın). Verilerin orijinal sırası A, B, C ise çıktı sırası A, B, C olacaktır. Şüpheci misiniz? Öyle olduğunu biliyorum, bu yüzden test ettim ve reklamı yapıldığı gibi çalıştığını keşfettim. Bu testten biraz sonra bu yazıda bahsedeceğiz. Paralelliği artırmanın yalnızca durum bilgisi olmayan işlemlerle veya ilişkisel ve değişmeli durum bilgisi olan işlemlerle yapılması gerektiğini unutmayın; bu, işlemlerin sırasını veya gruplandırmasını değiştirmenin sonucu etkilemeyeceği anlamına gelir.
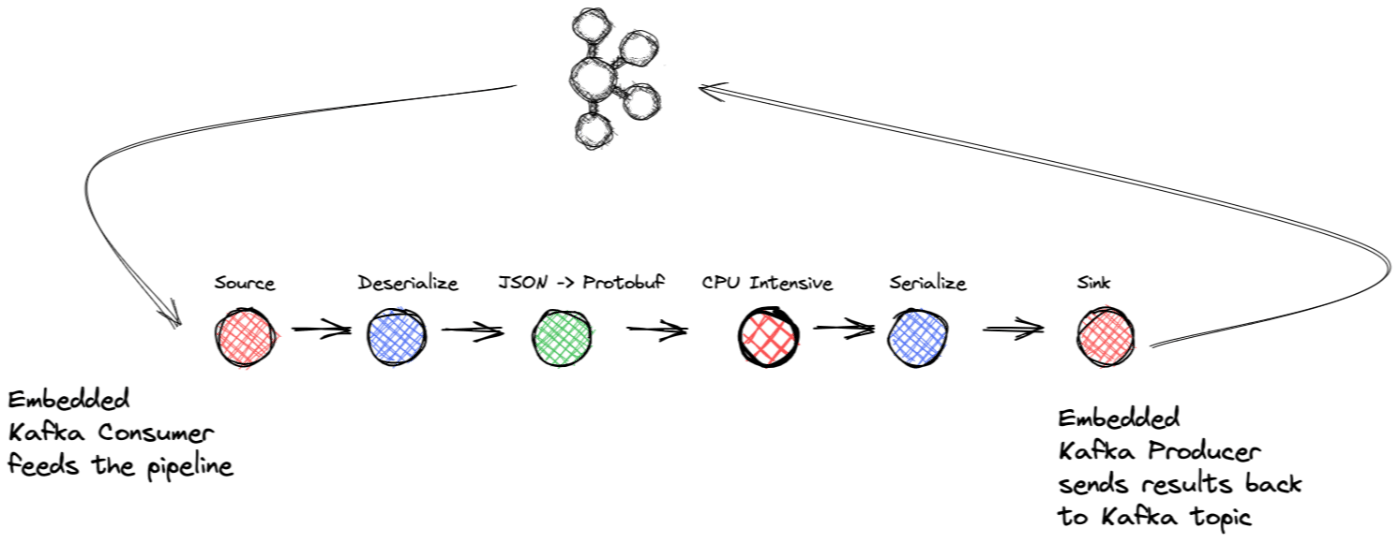
- Kaynak bloğu: .NET KafkaConsumer'ı ve
BufferBlocktemsilcisini sarmalama - Dönüşüm bloğu: Seri durumdan çıkarma
- Dönüşüm bloğu: Gelen JSON verilerini satın alma nesnesine eşleme
- Dönüşüm bloğu: CPU yoğun görev (simüle edilmiş)
- Dönüşüm bloğu: Serileştirme
- Hedef blok: .NET KafkaProducer ve
BufferBlocktemsilcisini sarmalama
Bir olay akışı uygulaması
Senaryomuz şöyle: Çevrimiçi mağazanızdan satın alma işlemlerinin kayıtlarını alan bir Kafka konunuz var ve gelen veri biçimi JSON'dur. Bu satın alma olaylarını, satın alma ayrıntılarına makine öğrenimi çıkarımı uygulayarak işlemek istiyorsunuz. Ayrıca, JSON kayıtlarını Protobuf biçimine dönüştürmek istiyorsunuz; çünkü bu, şirket genelindeki veri biçimidir. Tabii ki, uygulama için verim önemlidir. ML işlemleri CPU yoğun olduğundan uygulama verimini en üst düzeye çıkarmanın bir yoluna ihtiyacınız vardır, böylece uygulamanın bu bölümünü paralelleştirmenin avantajından yararlanırsınız.
Verileri ardışık düzende tüketme
Kaynak bloktan başlayarak akış uygulamasının kritik noktalarını gezelim. Daha önce ISourceBlock arayüzünün uygulanmasından bahsetmiştim ve BufferBlock aynı zamanda ISourceBlock da uyguladığından, onu tüm arayüz yöntemlerini karşılamak için bir temsilci olarak kullanacağız. Böylece kaynak blok uygulaması bir KafkaConsumer ve BufferBlock'u saracaktır. Kaynak bloğumuzun içinde, yegane sorumluluğu tüketicinin tükettiği kayıtları ara belleğe aktarması olan ayrı bir iş parçacığımız olacak. Buradan arabellek, kayıtları işlem hattındaki bir sonraki bloğa iletecektir.
Kaydı arabelleğe iletmeden önce ConsumeRecord ( Consumer.consume çağrısı tarafından döndürülür), anahtar ve değere ek olarak uygulama için kritik olan orijinal bölümü ve uzaklığı yakalayan bir Record soyutlaması ile sarılır ve Nedenini birazdan açıklayacağım. Ayrıca tüm işlem hattının Record soyutlaması ile çalıştığını da belirtmek gerekir; bu nedenle herhangi bir dönüşüm, anahtarı, değeri ve orijinal ofset gibi diğer önemli alanları saran yeni bir Record nesnesiyle sonuçlanır ve bunları tüm işlem hattı boyunca korur.
Blokları işleme
Uygulama, işlemeyi birkaç farklı bloğa ayırır. Her blok, işleme zincirindeki bir sonraki adıma bağlanır, böylece kaynak blok, seri durumdan çıkarma işlemini gerçekleştiren ilk bloğa bağlanır. .NET KafkaConsumer kayıtların seri durumdan çıkarılmasını gerçekleştirebilirken, tüketicinin serileştirilmiş veriyi aktarmasını ve bir Transform bloğunda seri durumdan çıkarma işlemini gerçekleştirmesini sağlıyoruz. Seri durumdan çıkarma, CPU yoğun olabilir, bu nedenle bunu işlem bloğuna koymak, gerekirse işlemi paralelleştirmemize olanak tanır.
Bu simüle edilmiş işleme bloğu, Veri Akışı blok çerçevesinin gücünden yararlandığımız yerdir. Bir Dataflow bloğunun örneğini oluşturduğunuzda, karşılaştığı her kayıt için geçerli olan bir temsilci Func örneği ve bir ExecutionDataflowBlockOptions örneği sağlarsınız. Dataflow bloklarını yapılandırmaktan daha önce bahsetmiştim ancak bunları burada tekrar hızlı bir şekilde inceleyeceğiz. ExecutionDataflowBlockOptions iki temel özelliği içerir: söz konusu blok için maksimum arabellek boyutu ve maksimum paralelleştirme derecesi.
Yoğun işlem bloğu, havuz bloğunu besleyen ve daha sonra bir .NET KafkaProducer'ı saran ve nihai sonuçları bir Kafka konusuna üreten bir serileştirme dönüşüm bloğuna iletir. Havuz bloğu aynı zamanda bir temsilci BufferBlock ve üretim için ayrı bir iş parçacığını kullanır. İş parçacığı arabellekten bir sonraki kullanılabilir kaydı alır. Daha sonra, DeliveryReport saran bir Action temsilcisinden geçen KafkaProducer.Produce yöntemini çağırır; üretici G/Ç iş parçacığı, üretim isteği tamamlandığında Action temsilcisini yürütür.
Ofsetlerin işlenmesi
Verileri Kafka ile işlerken, uygulamanızın belirli bir noktaya kadar başarıyla işlediği kayıtların uzaklıklarını (bir uzaklık, Kafka konusundaki bir kaydın mantıksal konumudur) periyodik olarak işlersiniz. Peki neden ofsetler yapılıyor? Bu cevaplaması kolay bir soru: Tüketiciniz kontrollü bir şekilde veya hata nedeniyle kapandığında, bilinen son taahhüt edilen ofsetten işleme devam edecektir. Denkleştirmelerin periyodik olarak gerçekleştirilmesiyle, tüketiciniz kayıtları yeniden işlemez veya uygulamanız birkaç kaydı işledikten sonra ancak işleme koymadan önce kapanırsa en azından minimum bir miktarı yeniden işlemez. Bu yaklaşım, en az bir kez işleme olarak bilinir; bu, kayıtların en az bir kez işlenmesini garanti eder ve hata durumunda belki bazıları yeniden işlenebilir, ancak alternatif veri kaybı riskini göze almak olduğunda bu harika bir seçenektir. Kafka aynı zamanda tam olarak bir kez işleme garantisi de sağlar ve bu blog yazısında işlemlere girmesek de, Kafka'daki işlemler hakkında daha fazla bilgiyi şurada bulabilirsiniz:
Ardışık düzen yaklaşımıyla en az bir kez işlemeyi nasıl garanti ederiz? Tek bir parametreyi (bir TopicPartitionOffset ) görevlendiren ve onu (diğer ofsetlerle birlikte) bir sonraki işleme için saklayan IConsumer.StoreOffset yöntemini kullanacağız . otomatik tamamlamanın Java API ile çalışma şekliyle çeliştiğini unutmayın.
Üretim aşamasında herhangi bir hata durumunda, uygulama hatayı günlüğe kaydeder ve kaydı tekrar iç içe geçmiş BufferBlock koyar, böylece üretici kaydı aracıya göndermeyi yeniden deneyecektir. Ancak bu yeniden deneme mantığı körü körüne yapılır ve pratikte muhtemelen daha sağlam bir çözüm isteyeceksiniz.
Performans etkileri
Artık uygulamanın nasıl çalıştığını anlattığımıza göre performans rakamlarına bakalım. Tüm testler yerel olarak bir macOS Big Sur (11.6) dizüstü bilgisayarda gerçekleştirildi; dolayısıyla bu senaryoda kat edeceğiniz mesafe farklılık gösterebilir. Performans testi kurulumu basittir:
- JSON formatında bir Kafka konusuna 1 milyon kayıt oluşturun. Bu adım önceden yapıldı ve test ölçümlerine dahil edilmedi.
- Kafka Veri Akışı özellikli uygulamayı başlatın ve tüm bloklar arasında paralelleştirmeyi 1 (varsayılan) olarak ayarlayın
- Uygulama, 1 milyon kaydı başarıyla işleyene kadar çalışır, ardından kapanır
- Tüm kayıtların işlenmesi için geçen süreyi kaydedin
| Kayıt Sayısı | Eşzamanlılık Faktörü | Süre (dakika) |
|---|---|---|
| 1 milyon | 1 | 38 |
| 1 milyon | 4 | 9 |
- Kafka konusuna 1M tam sayı (0-999,999) üretin
- Tamsayı türleriyle çalışacak şekilde referans uygulamasını değiştirin
- Uygulamayı simüle edilmiş uzak işlem bloğu için bir eşzamanlılık düzeyiyle çalıştırın; bir Kafka konusu oluşturun
- Uygulamayı dört eşzamanlılık düzeyiyle yeniden çalıştırın ve sayıları başka bir Kafka konusuna üretin
- Her iki sonuç konusundaki tamsayıları tüketmek ve bunları bellekteki bir dizide depolamak için bir program çalıştırın
- Her iki diziyi karşılaştırın ve aynı sırada olduklarını doğrulayın
Özet
Bu yazıda , sağlam, yüksek verimli bir olay akışı uygulaması oluşturmak için .NET Kafka istemcilerinin ve Görev Paralel Kitaplığının nasıl kullanılacağını anlattık. Kafka, yüksek performanslı olay akışı sağlar ve Görev Paralel Kitaplığı, tüm ayrıntıları işlemek için arabelleğe alma özelliğiyle eşzamanlı uygulamalar oluşturmak için yapı taşlarını sağlayarak geliştiricilerin iş mantığına odaklanmasına olanak tanır. Uygulamanın senaryosu biraz yapmacık olsa da, umarım iki teknolojiyi birleştirmenin faydasını görebilirsiniz. Bir şans ver-
L O A D I N G
. . . comments & more!
. . . comments & more!



