

































Jan 01, 1970
直接的需求优化系统:你的语言表达方式三维型号说真的是有一个实物奖励三维型号 经历过@textmodels
231 讀數
直接偏好优化:你的语言模型其实是一个奖励模型
路经 Writings, Papers and Blogs on Text Models5m2024/08/25
太長; 讀書
直接偏好优化 (DPO) 引入了一种更简单、更稳定的强化学习替代方案,用于将语言模型与人类偏好保持一致。通过消除对奖励建模和复杂训练程序的需求,DPO 提供了高效的微调,其性能可与基于 PPO 的 RLHF 等现有方法相媲美甚至超越,尤其是在情绪调节、总结和对话任务方面。作者:
(1) Rafael Rafailo,斯坦福学校生,相近的分享;一些全能原作者成员名单最前面已排序; (2)Archit Sharma,斯坦福二本大学,同样的供献;比较多初中级著者列于后面; (3)Eric Mitchel,斯坦福大家,相同提供;越来越多中级证书创作者列于前排; (4)Stefano Ermon,CZ Biohub; (5)克里斯托弗·曼宁(Christopher D. Manning),斯坦福二本大学(6)切尔西·芬恩,斯坦福高中。链接表
A.2 根据 Bradley-Terry 模型推导 DPO 目标
A.3 根据 Plackett-Luce 模型推导 DPO 目标
A.4 推导 DPO 目标函数的梯度和 A.5 引理 1 和 2 的证明
C 实验设置的更多细节和 C.1 IMDb 情绪实验和基线细节
D.1 最佳 N 基线对各种 N 的表现和 D.2 样本响应和 GPT-4 判断
抽象的
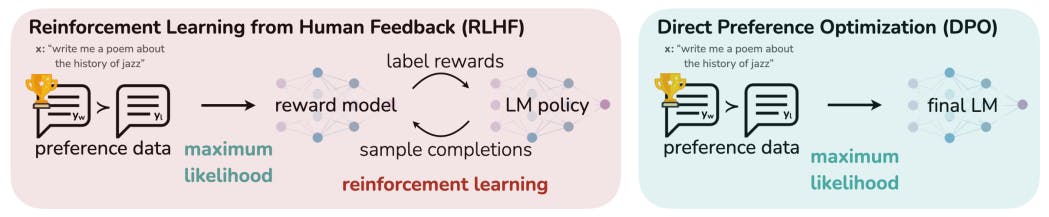
而是大总量无督促程序语言学英文3d模式 (LM) 能能练习非常广泛的地球基本常识和某些逻辑推理技能视觉效果,但随着其体能训练方法方式具体方法截然无督促,以至于太难明确的调控其情形。现存的领取一些可调控性的方式具体方法是获取3d模式合成较为产品的人间标记,并稍细调一下无督促程序语言学英文3d模式以贴合这部分喜欢,一般用从人间评议中确定增幅练习 (RLHF)。那么,RLHF 是个很复杂且一般不可靠的时,1要曲线拟合两个反映了人间喜欢的实物奖励制度3d模式,接下来用增幅练习稍细调一下巨型无督促程序语言学英文3d模式以最主要化这样可能的实物奖励制度,而不用紧急制动原3d模式很大。在本诗中,小编获取了 RLHF 中实物奖励制度3d模式的新技术指标化,能能以密封风格分离出相对的最有效的具体方法,让小编就能够仅用简简单单的做好分类盘亏来缓解标准 RLHF 的问题。形成形成的法求,小编又叫做随时喜欢网站优化 (DPO),可靠、效率且核算量轻,不用再在稍细调一下或完成大量超技术指标优化过程中从 LM 中取样。小编的试验阐明,DPO 能能稍细调一下 LM,使其与人间喜欢恢复同步,视觉效果与现存方式具体方法类似好也非常好。引起需要注意的是,用 DPO 确定稍细调一下在的调控代际负面情绪的功能地方以上了依托于 PPO 的 RLHF,和在汇报总结和单论交流中自动匹配或上升了回应产品,同時使用和体能训练方法方式具体方法在一起要简简单单得多。1 简介
在如此大的数值集上体能借鉴的新型无监管语言英文表达对实体模特 (LM) 获得了了另人大吃一惊的水平 [11, 7, 40, 8]。但,部分对实体模特是在具备几种指标、优先选择相关事宜和专业既能的一添加的数值上体能借鉴的。这里面部分指标和专业既能机会不合摸仿;这类,似乎自己都机会渴望自己都的人为智慧标识号助手下载熟悉多见的程序编写问题若要修复两者,但在添加二维码时,自己都渴望自己都的对实体模特喜爱于其体能借鉴数值中来源于的(机会令人震惊的)优水平标识号水平。都,自己都机会渴望自己都的语言英文表达对实体模特都可以发现到 50% 的人深信的多见错解,但自己都不过不渴望对实体模特在 50% 的查询个人中扬言一些错解是正常的!简单来说,从对实体模特如此诸多的基本常识和水平选出择其要求的死机和攻击行为关于营造安全性高、高的性能和人工工资控制的人为智慧模式至关重点 [26]。似乎现阶段的方法一般性选择提升借鉴 (RL) 来指导 LM 以适配我们人类习惯,
该参考文献。
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
標籤
相關故事
释放人工智能的力量。前沿技术的系统评价:摘要与介绍
#ai

成功云迁移的完整指南:策略和最佳实践 #cloud-migration
Jan 01, 1970

看不见的层面:为什么用户访谈是不可替代的资产 #startup
Jan 01, 1970

