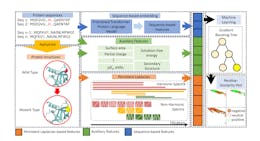
![Figure 5: The illustration of (a) point cloud, (b) basic simplices and (c) the filtration process and (d) Comparison between PH barcodes [50, 12] and the non-harmonic spectra of persistent Laplacians (PLs) [25] from the filtration process in (c). The x axis represents the filtration parameter f. By discretising the filtration region into equal-sized bins and adding all the Betti bars together, the topological invariants are summarized into persistent Betti numbers that acts a topological descriptor extracted from protein structures. Persistent Laplacians (PLs) [25] for thirteen points. The first non-zero eigenvalues of dimension 0, λ0(r), and dimension 1, λ1(r), of PLs are depicted in red. The harmonic spectra of PLs return all the topological invariants of PH, whereas the non-harmonic spectra of PLs capture the additional homotopic shape evolution of PLs during the filtration that are neglected by PH.](http://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-38h3s01.png?auto=format&fit=max&w=1920)






visit
Interrogating TopLabGBT's Computational Framework by@mutation
104 reads
Interrogating TopLabGBT's Computational Framework
by Mutation Technology PublicationsFebruary 17th, 2024
Too Long; Didn't Read
Discover the detailed methods utilized by TopLapGBT for predicting protein solubility changes, including spectral graph theory, persistent Laplacian, and transformer features. Gain insights into the computational framework driving this groundbreaking model in molecular biology research.People Mentioned
Authors:
(1) JunJie Wee, Department of Mathematics, Michigan State University; (2) Jiahui Chen, Department of Mathematical Sciences, University of Arkansas;(3) Kelin Xia, Division of Mathematical Sciences, School of Physical and Mathematical Sciences Nanyang Technological University & [email protected];
(4)Guo-Wei Wei, 1Department of Mathematics, Michigan State University, Department of Biochemistry and Molecular Biology, Michigan State University, Department of Electrical and Computer Engineering, Michigan State University & [email protected].
Table of Links
Software and resources, Code and Data Availability
Supporting Information, Acknowledgments & References
5 Materials and Methods
In this section, we endeavor to elucidate key mathematical and computational foundations that are instrumental for the work presented in this study. Specifically, we delve into spectral graph theory, simplicial complex, and persistent Laplacian methods, highlighting their significance in capturing topological and spectral properties essential for the characterization of proteins. Additionally, we discuss machine learning and deep learning paradigms, focusing on their role in processing, analyzing, and interpreting these complex features, especially within the confines of test datasets and validation settings.5.1 Persistent Laplacian characterization of proteins
Simplicial complex A simplicial complex is made up of a set of simplices and generalises beyond graph networks at higher dimensions [44, 45, 46, 47]. Every simplex is a finite set of vertices which can be interpreted as the atoms in a protein structure. Essentially, simplices can be a point (0-simplex), an edge (1-simplex), a triangle (2-simplex), a tetrahedron (3-simplex), or in higher dimensions, a p-simplex. In other words, a k-simplex σ k = {v0, v1, · · · , vk} is the convex hull formed by k + 1 affinely independent points v0, v1, · · · , vk as follows,
Persistent Laplacian Persistent Laplacian (PL) were first introduced by integrating graph Laplacian and multiscale filtration [25]. Analyzing the spectra of k-combinatorial Laplacian matrix allows both topological and geometric information (i.e. connectivity and robustness of simple graphs) to be obtained. However, this method is genuinely free of metrics or coordinates, which induced too little topological and geometric information that can be used to describe a single configuration.
5.2 Persistent Laplacian descriptors
5.3 Persistent Homology
Persistent homology is part of the harmonic spectra of PL. The homology groups in PH illustrate the persistence of topological invariants, hence providing the harmonic spectral information in PL. The site- and element-specific PH features are generated in a similar way as compared to PL. Similar to PL, filtration construction is also employed to PH. For the zero dimension, the filtration parameter can be discretized into several equally spaced bins, namely [0, 0.5], (0.5, 1], · · · , (5.5, 6]A. The death value of the bars are summed in each bin resulting in 12 ˚ ×18 features.
5.4 Transformer Features
Recently, we have seen significant advancements in modelling protein properties using largescale protein transformer models trained on hundreds of millions of sequences. These models, like ESM [33] (evolutionary scale modeling) and ProtTrans[34, 35], have demonstrated impressive performance. Moreover, hybrid fine-tuning approaches that leverage both local and global evolutionary data have proven to enhance these models even further. For instance, eUniRep is an improved LSTM-based UniRep model achieved through fine-tuning with knowledge extracted from local multiple sequence alignments (MSAs). Additionally, the ESM model can be fine-tuned using either downstream task data or local MSAs. In our research, we employed the ESM-1b transformer, a model that falls under the transformer architecture. This particular variant was trained on a dataset of 250 million sequences using a masked filling procedure and boasts an architecture comprising 34 layers with a whopping 650 million parameters. The ESM transformer’s primary role in our work was to generate sequence embeddings. At each layer of the ESM model, it encoded a sequence of length L into a matrix sized at 1,280×L, excluding the start and terminal tokens. For our study, we utilized the sequence representation derived from the final (34th) layer and computed the average along the sequence length axis, resulting in a 1,280-component vector.5.5 Performance Metrics
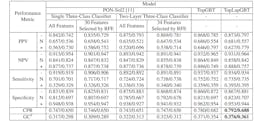
PPV and NPV assesses the true positive and true negative proportion of the predicted results for each solubility class. PPV and NPV are computed based on TP, TN, FP and FN which represents the true positive, true negative, false positive and false negative values for each solubility class. For each solubility class, PPV and NPV can be computed by:
This paper is under CC 4.0 license.
L O A D I N G
. . . comments & more!
. . . comments & more!