TopLapGBT combines structure-based and sequence-based features for accurate protein solubility prediction. Its performance surpasses existing models, demonstrating significant improvements in key metrics like CPR and GC2. With validation on independent test sets, TopLapGBT emerges as a game-changer in protein engineering and drug discovery.
People Mentioned
Authors:
(1) JunJie Wee, Department of Mathematics, Michigan State University;
(2) Jiahui Chen, Department of Mathematical Sciences, University of Arkansas;
(3) Kelin Xia, Division of Mathematical Sciences, School of Physical and Mathematical Sciences Nanyang Technological University & [email protected];
(4)Guo-Wei Wei, 1Department of Mathematics, Michigan State University, Department of Biochemistry and Molecular Biology, Michigan State University, Department of Electrical and Computer Engineering, Michigan State University & [email protected].
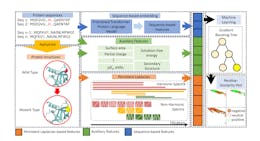
TopLapGBT integrates both structure-based and sequence-based features, derived from protein structures and sequences respectively, into a unified model. Our architecture comprises three distinct embedding modules: persistent Laplacian-based embeddings, sequence-based embeddings, and auxiliary feature embeddings, all of which feed into an ensemble classifier as depicted in Figure 1.
In the persistent Laplacian-based feature embedding module, we employ persistent Laplacian techniques to generate features that encapsulate the structural attributes of proteins both pre- and post-mutation. This approach is particularly effective in capturing the structural alterations induced by mutations within the localized neighborhoods of the mutation sites. Mathematically, the persistent Laplacian builds a sequence of simplicial complexes through a filtration process, thereby characterizing atom-atom interactions across multiple scales (details in the Methods section). In the sequence-based feature embedding module, a pre-trained transformer model generates latent feature vectors extracted from protein sequences. Specifically, the transformer model used here is a 650M-parameter protein language model, trained on a corpus of 250M protein sequences spanning multiple organisms [39]. Finally, the auxiliary feature embedding module incorporates a variety of attributes such as surface area, partial charge, pKa shifts, solvation free energy, and secondary structural information, synthesized from both protein sequences and structures. These three distinct sets of feature embeddings are subsequently concatenated to produce a comprehensive feature vector. This vector is then fed into a gradient-boosting tree classifier to categorize the mutation-induced samples.
2.2 Performance of TopLapGBT on PON-Sol2 dataset
In our study, we utilize the dataset employed by PON-Sol2 as detailed in [11]. The dataset is comprised of 6,328 mutation samples, originating from 77 distinct proteins. These samples are categorized into three labels: decrease in solubility, increase in solubility, and no change in solubility. Specifically, the dataset contains 3,136 samples demonstrating a decrease in solubility, 1,026 samples showing an increase, and 2,166 samples with no change. Notably, the dataset exhibits a class imbalance, with a ratio of 1 : 0.69 : 0.34, indicating a bias towards samples that exhibit a decrease in solubility. To assess the performance of our model, we initially carry out a random 10-fold cross-validation on the dataset. Subsequently, an independent blind test prediction is executed to provide further validation of the model’s efficacy.
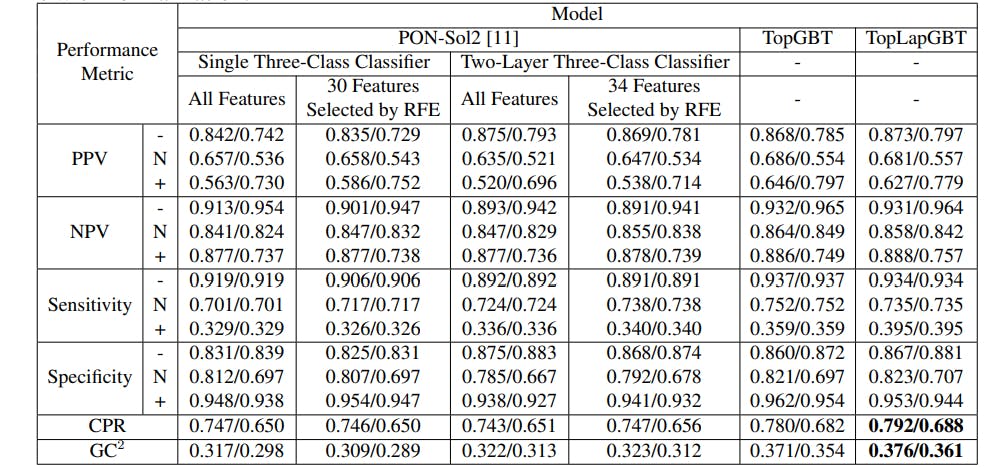
In Table 1, we present a comparative analysis of the performance of existing classifiers by PON-Sol [5] and PON-Sol2 [11] against our proposed model, TopLapGBT, using 10-fold cross-validation. It should be noted that PON-Sol2 incorporates feature selection techniques such as recursive feature elimination (RFE). To provide a robust assessment of TopLapGBT’s performance, we conduct 10 repeated runs, and the mean values of these runs are reported to account for any randomness in the model’s output.
Performance evaluation of our model, TopLapGBT, is conducted using a range of metrics, including Positive Predictive Value (PPV), Negative Predictive Value (NPV), Sensitivity, Specificity, Correct Prediction Ratio (CPR), and Generalized Squared Correlation (GC2 ). PPV and NPV quantify the proportions of correct positive and negative predictions for each solubility class, respectively. Given that we are dealing with a K-class problem with three distinct solubility classes, CPR and GC2 are particularly relevant for providing a holistic view of the model’s performance [40]. Specifically, CPR measures the overall accuracy of the model, while GC2 quantifies the correlation coefficient of the classification, ranging from 0 to 1. Larger values for these metrics denote better performance. Importantly, due to the class imbalance in the number of mutation samples across the categories, all performance metrics are normalized to ensure a robust and reliable evaluation of the model’s efficacy (further details are elaborated in the Methods section).
Table 1: Comparison of performance metrics between TopLapGBT and both single layer and double layer classifiers of PON-Sol2 in the 10-fold crossvalidation. The negative solubility samples are denoted as ”-” whereas the positive solubility change samples are denoted as ”+”. The samples with no solubility change are denoted as ”N”. Performance metrics include the positive predicted values (PPV), negative predicted values (NPV), sensitivity, specificity, correct prediction ratio (CPR) and generalised correlation (GC2 ). PPV refers to the proportions of positive predictions for each solubility class while NPV refers to the proportions of negative predictions for each solubility class. CPR calculates the percentage of correctly classified samples while GC2 measures the correlation coefficient of the classification. All normalized metrics are also reported. For each metric, the first value is without normalization while the second one is with normalization.
The proposed model, TopLapGBT, demonstrates significant performance gains over existing featurization methods in PON-Sol2 across all evaluation metrics [11]. Specifically, normalized CPR and GC2 scores of TopLapGBT stand at 0.688 and 0.361, marking improvements of 4.88% and 15.71% over PON-Sol2, respectively. These gains underscore the merit of incorporating both structure-based and sequence-based features into the model. To elucidate the contribution of Persistent Laplacian (PL)-based features, we also present a comparative analysis with our TopGBT model in Table 1. The TopGBT model utilizes persistent homology-based embeddings alongside auxiliary and pre-trained transformer features. While TopGBT still outperforms all existing PON-Sol2 models, the incorporation of PL-based features in TopLapGBT leads to an incremental improvement of 1% and 2% in CPR and GC2 metrics, respectively. This validates our approach of leveraging Persistent Laplacian to comprehensively capture both the topological and homotopic nuances in the evolution of protein structures.
2.3 Performance of TopLapGBT on independent test set
To robustly assess the performance of TopLapGBT, we subjected it to an independent test using the same dataset employed by PON-Sol2 [11]. In this validation, TopLapGBT consistently outperformed all five existing models, as evidenced in Table 2. Specifically, TopLapGBT registers a normalized CPR of 0.564 and a normalized GC2 of 0.185, surpassing PON-Sol2 by 3.49% and 17.83%, respectively. Relative to TopGBT, the inclusion of PL-based features in TopLapGBT yielded incremental gains in both CPR and GC2 metrics, thereby further substantiating the utility of Persistent Laplacian in capturing the homotopic shape evolution within protein structures.















![Figure 1: The illustration of the workflow for TopLapGBT. Protein sequences are first preprocessed by AlphaFold 2 to generate wild type protein structures. Mutant proteins are generated from the Jackal software [38]. The structure-based features from persistent Laplacian, auxiliary and sequence-based features are then concatenated to form a long feature input for gradient boosting tree to classify the protein solubility changes upon mutation. The predicted labels are also analyzed on Residue-Similarity (R-S) plots.](http://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-0683rq4.png?auto=format&fit=max&w=3840)