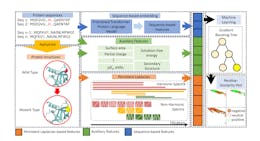
![Figure 2: (a) The definitions of the structural regions on the protein label 213133708 with mutation ID: I283W. For both wild type and mutant type, amino acids in the proteins are classified under surface or interior regions based on the rASA of the residue. The residue ID 283 of protein label 213133708 was mutated from isoleucine (interior region) to trytophan (surface region). Structures are plotted with the software Illustrate[42]. (b) A comparison of performance of TopLapGBT among different mutation region types. The y-axis represents the region type for the original residue and the x-axis represents the region type for the mutated residue. The numbers indicated in each cell corresponds to the number of mutation samples in each regionregion mutation pair. The accuracy scores (CPR) for both interior-interior and interior-surface are 0.813 and 0.812 while the accuracy score for both surface-interior and surface-surface are 0.725 and 0.730.](http://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-2f93rxd.png?auto=format&fit=max&w=3840)






visit
Unveiling Protein Solubility Patterns: Insights from TopLapGBT's Performance Analysis by@mutation
126 reads
Unveiling Protein Solubility Patterns: Insights from TopLapGBT's Performance Analysis
by Mutation Technology PublicationsFebruary 16th, 2024
Too Long; Didn't Read
Explore TopLapGBT's analysis of protein solubility patterns, offering insights into mutation impact and protein engineering. Leveraging structural data from AlphaFold2 and advanced machine learning techniques, TopLapGBT reveals nuanced relationships within protein structures. Discover its performance across mutation regions and types, revolutionizing biomolecular research.People Mentioned
Authors:
(1) JunJie Wee, Department of Mathematics, Michigan State University; (2) Jiahui Chen, Department of Mathematical Sciences, University of Arkansas;(3) Kelin Xia, Division of Mathematical Sciences, School of Physical and Mathematical Sciences Nanyang Technological University & [email protected];
(4)Guo-Wei Wei, 1Department of Mathematics, Michigan State University, Department of Biochemistry and Molecular Biology, Michigan State University, Department of Electrical and Computer Engineering, Michigan State University & [email protected].
Table of Links
Software and resources, Code and Data Availability
Supporting Information, Acknowledgments & References
3 Discussion
The performance of machine learning models generally relies on the nature of the input features. In our model, the PL-based features depend on one main element which is the quality of the protein structures from AlphaFold 2 (AF2). The quality of AF2 structures are crucial in determining the performance of TopLapGBT. Recently, AF2 structures have been reported to achieve comparable performance to nuclear magnetic resonance (NMR) structures while ensemble methods can be used to enhance the performance by combining multiple NMR structures [1]. This allows AF2 structures to serve as a practical substitute for experimental structural data. Although AF2 structures are not as reliable as X-ray structures, the fusion of sequencebased pre-trained transformer features and PL-based features provides robust featurization even for low quality AF2 structural data. PL elucidates the precise mutation geometry and topology, while sequence-based pre-trained transformer features capture evolutionary patterns from an extensive sequence library. This synergy holds significance and can be applied to a diverse range of other challenges in the field of biomolecular research. For the rest of this section, we analyze the model’s performance based on the region of the mutations and the type of mutations. We also discuss the performance of different feature types using the Residue-Similarity plots.
3.1 Performance analysis based on different mutation regions
To delve deeper into the model’s performance, we categorize mutation samples based on their structural regions: interior and surface, as depicted in Figure 2 pre- and post-mutations. These regions are defined by their relative accessible solvent area (rASA), using a cutoff value c. A residue at the mutation site is classified as buried or interior if its rASA falls below this cutoff. While the discrete nature of c initially raised concerns, given that amino acids have a continuous exposure profile, empirical analyses on databases from organisms like Escherichia coli, Saccharomyces cerevisiae, and Homo sapiens have shown that an optimal rASA cutoff of approximately 25% is effective for distinguishing between surface and interior residues [41]. In our analysis, we apply this framework to identify surface and interior residues in the solubility dataset. We observe that some mutation sites undergo a regional transition, moving from one structural domain to another, consequent to the mutation.
3.2 Performance analysis based on different mutation types
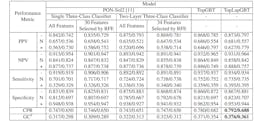
Switching focus to mutation types, our model’s capability in classifying solubility changes also merits exploration across the 20 distinct amino acid types in the dataset. In addition to this, we subgroup amino acids as charged, polar, hydrophobic, or special case. Table S1 enumerates the sample counts for each mutation group pair. Figure 3(a) displays accuracy scores for each mutation group pair, while Figure 3(b) shows scores for each amino acid pair. Notably, the special-charged and special-polar groups register the highest accuracy, whereas the polarhydrophobic and polar-special groups underperform. One plausible reason could be the inherent complexity in accurately classifying mutations with non-negative solubility changes. It’s worth noting that PON-Sol2 employed a two-layer classifier to improve classification [11]. Our results indicate that TopLapGBT surpasses the performance of this two-layer system.
3.3 Feature analysis based on Residue-Similarity plots
The Residue Similarity Index (RSI) serves as a potent metric for evaluating the efficacy of dimensionality reduction in both clustering and classification contexts [43]. RSI has proven its value in generating classification accuracy scores that align well with supervised methods in single-cell typing. When applied to our solubility change dataset, Residue-Similarity (R-S) plots can be constructed to scrutinize how the Residue Index (RI) and Similarity Index (SI) may indicate the quality of cluster separation.
This paper is under CC 4.0 license.
L O A D I N G
. . . comments & more!
. . . comments & more!