













































Jan 01, 1970
Comment les atomes ont fixé le flux par@bowheart
1,933 lectures
Comment les atomes ont fixé le flux
par Josh Claunch13m2023/06/05
Trop long; Pour lire
L'architecture Flux résonne dans tous les gestionnaires d'état React modernes. Les bibliothèques atomiques répondent mieux que Flux à la vision originale de Flux en offrant une meilleure évolutivité, autonomie, division du code, gestion du cache, organisation du code et primitives pour le partage d'état.
Recoil a introduit le modèle atomique dans le monde React . Ses nouveaux pouvoirs se sont fait au prix d'une courbe d'apprentissage abrupte et de ressources d'apprentissage rares.
Table des matières
- Flux
- Arbres de dépendance
- Le modèle singleton
- Retour aux sources
- La loi de Déméter
- Les héros
- Zedux
- Le modèle atomique
- Conclusion
Flux
Si vous ne connaissez pas Flux, voici un aperçu rapide :
Outre Redux , toutes les bibliothèques basées sur Flux ont essentiellement suivi ce modèle : une application a plusieurs magasins. Il n'y a qu'un seul répartiteur dont le travail consiste à fournir des actions à tous les magasins dans le bon ordre. Cet "ordre approprié" signifie trier dynamiquement les dépendances entre les magasins.
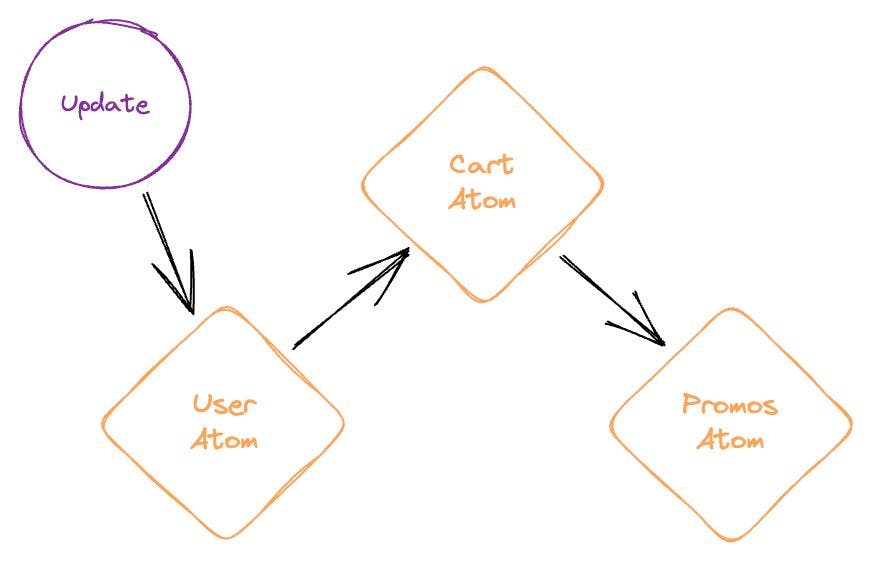
Prenons l'exemple d'une configuration d'application de commerce électronique :
Les objets d'une application Flux sont fortement découplés et adhèrent très fortement à la , le principe selon lequel chaque objet d'un système doit en savoir le moins possible sur les autres objets du système.
Arbres de dépendance
Il s'avère que les dépendances entre les conteneurs d'états isolés sont inévitables. En fait, pour garder le code modulaire et DRY, vous devriez utiliser fréquemment d'autres magasins.
// This example uses Facebook's own `flux` library PromosStore.dispatchToken = dispatcher.register(payload => { if (payload.actionType === 'add-to-cart') { // wait for CartStore to update first: dispatcher.waitFor([CartStore.dispatchToken]) // now send the request sendPromosRequest(UserStore.userId, CartStore.items).then(promos => { dispatcher.dispatch({ actionType: 'promos-fetched', promos }) }) } if (payload.actionType === 'promos-fetched') { PromosStore.setPromos(payload.promos) } }) CartStore.dispatchToken = dispatcher.register(payload => { if (payload.actionType === 'add-to-cart') { // wait for UserStore to update first: dispatcher.waitFor([UserStore.dispatchToken]) if (UserStore.canBuy(payload.item)) { CartStore.addItem(payload.item) } } })
D'autres implémentations de Flux comme Flummox et Reflux ont amélioré l'expérience passe-partout et de débogage. Bien que très utilisable, la gestion des dépendances était le seul problème persistant qui tourmentait toutes les implémentations de Flux. Utiliser un autre magasin était moche. Les arbres de dépendance profondément imbriqués étaient difficiles à suivre.
Le modèle singleton
Nous savons tous comment Redux est arrivé en rugissant pour sauver la situation. Il a abandonné le concept de magasins multiples au profit d'un modèle singleton. Désormais, tout peut accéder à tout le reste sans aucune "dépendance".
Les réducteurs sont purs, donc toute logique traitant de plusieurs tranches d'état doit sortir du magasin. La communauté a établi des normes pour la gestion des effets secondaires et de l'état dérivé. Les magasins Redux sont magnifiquement débogables. Le seul défaut majeur de Flux que Redux n'a pas réussi à corriger à l'origine était son passe-partout.
a ensuite simplifié le tristement célèbre passe-partout de Redux. Ensuite, Zustand a supprimé quelques peluches au prix d'une certaine puissance de débogage. Tous ces outils sont devenus extrêmement populaires dans le monde React.
Retour aux sources
Le succès de l'approche singleton soulève la question suivante : vers quoi Flux voulait-il en venir ? Pourquoi avons-nous jamais voulu plusieurs magasins?
Raison #1 : Autonomie
Avec plusieurs magasins, les pièces d'État sont réparties dans leurs propres conteneurs autonomes et modulaires. Ces magasins peuvent être testés isolément. Ils peuvent également être partagés facilement entre les applications et les packages.Raison #2 : Fractionnement de code
Ces magasins autonomes peuvent être divisés en morceaux de code distincts. Dans un navigateur, ils peuvent être chargés paresseusement et branchés à la volée.
Les réducteurs de Redux sont également assez faciles à diviser en code. Grâce à replaceReducer , la seule étape supplémentaire consiste à créer le nouveau réducteur combiné. Cependant, d'autres étapes peuvent être nécessaires lorsque des effets secondaires et des intergiciels sont impliqués.
Raison #3 : Primitives Standardisées
Avec le modèle singleton, il est difficile de savoir comment intégrer l'état interne d'un module externe au sien. La communauté Redux a introduit le modèle Ducks pour tenter de résoudre ce problème. Et ça marche, au prix d'un petit passe-partout.
Raison #4 : Évolutivité
Le modèle singleton est étonnamment performant. Redux l'a prouvé. Cependant, son modèle de sélection a surtout une limite supérieure dure. J'ai écrit quelques réflexions à ce sujet dans . Un grand arbre de sélection coûteux peut vraiment commencer à traîner, même en prenant un contrôle maximal sur la mise en cache.
Raison #5 : Destruction
La destruction de l'état n'est pas trop difficile dans Redux. Tout comme dans l'exemple de fractionnement de code, il suffit de quelques étapes supplémentaires pour supprimer une partie de la hiérarchie des réducteurs. Mais c'est encore plus simple avec plusieurs magasins - en théorie, vous pouvez simplement détacher le magasin du répartiteur et lui permettre d'être ramassé.Raison #6 : Colocation
C'est le gros problème que Redux, Zustand et le modèle singleton en général ne gèrent pas bien. Les effets secondaires sont séparés de l'état avec lequel ils interagissent. La logique de sélection est séparée de tout. Alors que Flux multi-magasins était peut-être trop colocalisé, Redux est allé à l'extrême opposé.
Résumé des motifs
Maintenant, si vous connaissez la bibliothèque OG Flux, vous savez que ce n'était pas génial du tout. Le répartiteur adopte toujours une approche globale - répartissant chaque action dans chaque magasin. Le tout avec des dépendances informelles/implicites a également rendu le fractionnement et la destruction du code moins que parfaits.
La loi de Déméter
Quelle est exactement cette soi-disant "loi"? De :
- Chaque unité ne doit avoir qu'une connaissance limitée des autres unités : uniquement les unités "étroitement" liées à l'unité actuelle.
- Chaque unité ne doit parler qu'à ses amis ; ne parlez pas aux étrangers.
- Se couple étroitement aux détails de mise en œuvre d'un autre magasin.
- Utiliser des magasins qu'il n'a pas besoin de connaître .
- Utiliser n'importe quel autre magasin sans déclarer explicitement une dépendance à ce magasin.
En termes de banane, une banane ne devrait pas éplucher une autre banane et ne devrait pas parler à une banane dans un autre arbre. Cependant, il peut parler à l'autre arbre si les deux arbres installent d'abord une ligne téléphonique banane.
Eh bien, les dépendances inter-magasins font naturellement partie d'un bon système modulaire. Si un magasin doit ajouter une autre dépendance, il doit le faire et le faire aussi explicitement que possible . Voici à nouveau une partie de ce code Flux :
PromosStore.dispatchToken = dispatcher.register(payload => { if (payload.actionType === 'add-to-cart') { // wait for CartStore to update first: dispatcher.waitFor([CartStore.dispatchToken]) // now send the request sendPromosRequest(UserStore.userId, CartStore.items).then(promos => { dispatcher.dispatch({ actionType: 'promos-fetched', promos }) }) } if (payload.actionType === 'promos-fetched') { PromosStore.setPromos(payload.promos) } })
PromosStore a plusieurs dépendances déclarées de différentes manières - il attend et lit à partir de CartStore et il lit à partir de UserStore . La seule façon de découvrir ces dépendances est de rechercher des magasins dans l'implémentation de PromosStore.
Contrairement aux héros de cette histoire :
Les héros
En 2020, est entré en trébuchant sur la scène. Bien qu'un peu maladroit au début, il nous a appris un nouveau modèle qui a ravivé l'approche multi-magasins de Flux.
// a Recoil atom const greetingAtom = atom({ key: 'greeting', default: 'Hello, World!', })
// a Jotai atom const greetingAtom = atom('Hello, World!')
// a (better?) Jotai atom const greetingAtom = atom('Hello, World!') greetingAtom.debugLabel = 'greeting'
La courbe d'apprentissage. Les atomes sont différents . Comment rendons-nous ces concepts accessibles aux développeurs de React ?
- Dev X et débogage. Comment rendons-nous les atomes détectables ? Comment suivez-vous les mises à jour ou appliquez-vous les bonnes pratiques ?
- Migration incrémentielle pour les bases de code existantes. Comment accéder aux boutiques externes ? Comment gardez-vous la logique existante intacte ? Comment éviter une réécriture complète ?
Plugins. Comment rendre le modèle atomique extensible ? Peut- il gérer toutes les situations possibles ?
- Injection de dépendance. Les atomes définissent naturellement les dépendances, mais peuvent-ils être échangés pendant les tests ou dans différents environnements ?
- La loi de Déméter. Comment masquer les détails de mise en œuvre et empêcher les mises à jour dispersées ?
Zedux
Zedux est enfin entré en scène il y a quelques semaines. Développé par une société Fintech à New York - la société pour laquelle je travaille - Zedux n'a pas seulement été conçu pour être rapide et évolutif, mais également pour offrir une expérience de développement et de débogage élégante.
// a Zedux atom const greetingAtom = atom('greeting', 'Hello, World!')
Alors, quel est exactement le modèle atomique ?
Le modèle atomique
Ces bibliothèques atomiques présentent de nombreuses différences - elles ont même des définitions différentes de ce que signifie "atomique". Le consensus général est que les atomes sont de petits conteneurs d'états isolés et autonomes mis à jour de manière réactive via un graphe acyclique dirigé.
- Autonomie - Les atomes peuvent être testés et utilisés complètement isolés.
- Fractionnement de code - Importez un atome et utilisez-le ! Aucune considération supplémentaire requise.
- Primitives standardisées - Tout peut exposer un atome pour une intégration automatique.
- Évolutivité - Les mises à jour n'affectent qu'une petite partie de l'arborescence d'état.
- Destruction - Arrêtez simplement d'utiliser un atome et tout son état est récupéré.
- Colocation - Les atomes définissent naturellement leur propre état, leurs effets secondaires et leur logique de mise à jour.
Les API simples et l'évolutivité font à elles seules des bibliothèques atomiques un excellent choix pour chaque application React. Plus de puissance et moins passe-partout que Redux ? Est-ce un rêve ?
Conclusion
Quel voyage ! Le monde de la gestion d'état React ne cesse de surprendre, et je suis tellement content d'avoir fait du stop.
Cet article est le deuxième d'une série de ressources d'apprentissage que je produis pour aider les développeurs de React à comprendre comment fonctionnent les bibliothèques atomiques et pourquoi vous voudrez peut-être en utiliser une. Consultez le premier article - Évolutivité : le niveau perdu de la gestion de l'état de réaction .
L O A D I N G
. . . comments & more!
. . . comments & more!



