













































Jan 01, 1970
Como os átomos fixam o fluxo por@bowheart
1,933 leituras
Como os átomos fixam o fluxo
por Josh Claunch13m2023/06/05
Muito longo; Para ler
A arquitetura do Flux ecoa em todos os gerenciadores de estado modernos do React. As bibliotecas atômicas cumprem a visão original do Flux melhor do que o Flux jamais poderia, oferecendo melhor escalabilidade, autonomia, divisão de código, gerenciamento de cache, organização de código e primitivas para compartilhamento de estado.
Recoil introduziu o modelo atômico no mundo React . Seus novos poderes vieram à custa de uma curva de aprendizado íngreme e recursos de aprendizado escassos.
Índice
- Fluxo
- Árvores de Dependência
- O Modelo Singleton
- Voltar à rotina
- A Lei de Deméter
- Os heróis
- Zedux
- O modelo atômico
- Conclusão
Fluxo
Se você não conhece o Flux, aqui vai um resumo:
Além do Redux , todas as bibliotecas baseadas no Flux seguiram basicamente este padrão: um aplicativo tem várias lojas. Existe apenas um Despachante cujo trabalho é alimentar ações para todas as lojas na ordem adequada. Essa "ordem adequada" significa classificar dinamicamente as dependências entre as lojas.
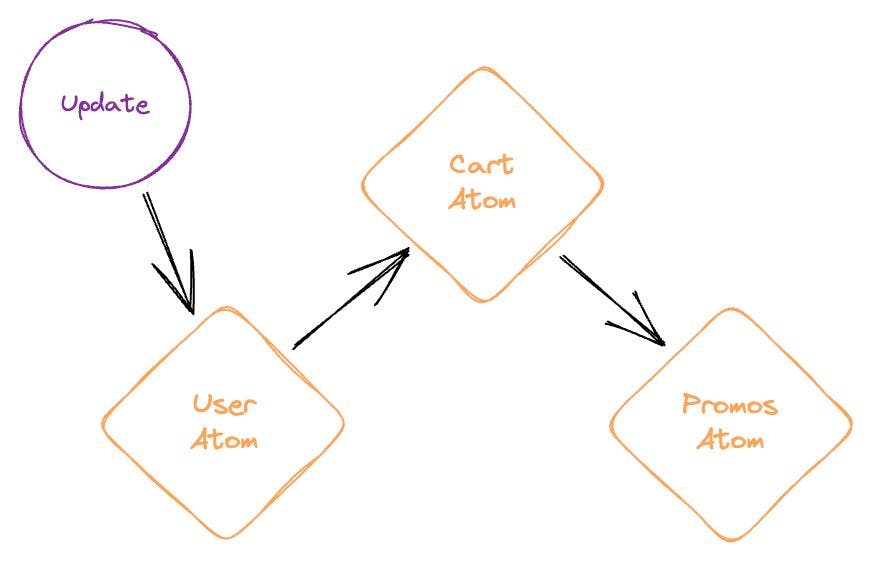
Por exemplo, considere a configuração de um aplicativo de comércio eletrônico:
Os objetos dentro de um aplicativo Flux são altamente desacoplados e seguem fortemente a , o princípio de que cada objeto dentro de um sistema deve saber o mínimo possível sobre os outros objetos do sistema.
Árvores de Dependência
Acontece que as dependências entre contêineres de estado isolados são inevitáveis. Na verdade, para manter o código modular e DRY, você deve usar outras lojas com frequência.
// This example uses Facebook's own `flux` library PromosStore.dispatchToken = dispatcher.register(payload => { if (payload.actionType === 'add-to-cart') { // wait for CartStore to update first: dispatcher.waitFor([CartStore.dispatchToken]) // now send the request sendPromosRequest(UserStore.userId, CartStore.items).then(promos => { dispatcher.dispatch({ actionType: 'promos-fetched', promos }) }) } if (payload.actionType === 'promos-fetched') { PromosStore.setPromos(payload.promos) } }) CartStore.dispatchToken = dispatcher.register(payload => { if (payload.actionType === 'add-to-cart') { // wait for UserStore to update first: dispatcher.waitFor([UserStore.dispatchToken]) if (UserStore.canBuy(payload.item)) { CartStore.addItem(payload.item) } } })
Outras implementações do Flux, como Flummox e Reflux, melhoraram o clichê e a experiência de depuração. Embora muito utilizável, o gerenciamento de dependências era o único problema persistente que afetava todas as implementações do Flux. Usar outra loja parecia feio. Árvores de dependência profundamente aninhadas eram difíceis de seguir.
O Modelo Singleton
Todos nós sabemos como o Redux apareceu para salvar o dia. Ele abandonou o conceito de várias lojas em favor de um modelo singleton. Agora tudo pode acessar todo o resto sem nenhuma "dependência".
Os redutores são puros, portanto, toda a lógica que lida com várias fatias de estado deve ir para fora do armazenamento. A comunidade criou padrões para gerenciar os efeitos colaterais e o estado derivado. As lojas Redux são lindamente depuráveis. A única grande falha de fluxo que o Redux originalmente não conseguiu consertar foi seu clichê.
Mais tarde, simplificou o infame clichê do Redux. Então Zustand removeu algumas penugens ao custo de algum poder de depuração. Todas essas ferramentas se tornaram extremamente populares no mundo React.
Voltar à rotina
O sucesso da abordagem singleton levanta a questão: o que o Flux queria dizer em primeiro lugar? Por que queremos várias lojas?
Razão # 1: Autonomia
Com várias lojas, os pedaços de estado são divididos em seus próprios contêineres modulares e autônomos. Essas lojas podem ser testadas isoladamente. Eles também podem ser compartilhados facilmente entre aplicativos e pacotes.Razão nº 2: divisão de código
Esses armazenamentos autônomos podem ser divididos em blocos de código separados. Em um navegador, eles podem ser carregados lentamente e conectados em tempo real.
Os redutores do Redux também são bastante fáceis de dividir em código. Graças a replaceReducer , a única etapa extra é criar o novo redutor combinado. No entanto, mais etapas podem ser necessárias quando efeitos colaterais e middleware estão envolvidos.
Razão #3: Primitivos Padronizados
Com o modelo singleton, é difícil saber como integrar o estado interno de um módulo externo com o seu. A comunidade Redux introduziu o padrão Ducks como uma tentativa de resolver isso. E funciona, ao custo de um pequeno clichê.
Razão #4: Escalabilidade
O modelo singleton tem um desempenho surpreendente. Redux provou isso. No entanto, seu modelo de seleção tem um limite superior rígido. Escrevi alguns pensamentos sobre isso . Uma árvore seletora grande e cara pode realmente começar a se arrastar, mesmo ao assumir o controle máximo sobre o armazenamento em cache.
Razão # 5: Destruição
Destruir o estado não é muito difícil no Redux. Assim como no exemplo de divisão de código, são necessárias apenas algumas etapas extras para remover uma parte da hierarquia do redutor. Mas ainda é mais simples com várias lojas - em teoria, você pode simplesmente separar a loja do despachante e permitir que ela seja coletada como lixo.Razão #6: Colocação
Este é o grande problema que Redux, Zustand e o modelo singleton em geral não lidam bem. Os efeitos colaterais são separados do estado com o qual eles interagem. A lógica de seleção é separada de tudo. Embora o Flux de várias lojas talvez estivesse muito localizado, o Redux foi para o extremo oposto.
Resumo dos motivos
Agora, se você conhece a biblioteca OG Flux, sabe que na verdade ela não era boa em nada disso. O despachante ainda adota uma abordagem global - despachando cada ação para cada loja. A coisa toda com dependências informais/implícitas também tornou a divisão e destruição de código menos do que perfeita.
A Lei de Deméter
O que exatamente é essa chamada "lei"? Da :
- Cada unidade deve ter apenas conhecimento limitado sobre outras unidades: apenas unidades "estreitamente" relacionadas à unidade atual.
- Cada unidade deve falar apenas com seus amigos; não fale com estranhos.
- Acoplando-se firmemente aos detalhes de implementação de outra loja.
- Usando lojas que não precisam saber .
- Usar qualquer outra loja sem declarar explicitamente uma dependência dessa loja.
Em termos de banana, uma banana não deve descascar outra banana e não deve falar com uma banana em outra árvore. No entanto, ele pode falar com a outra árvore se as duas árvores conectarem primeiro uma linha telefônica banana.
Bem, as dependências entre lojas são uma parte natural de um bom sistema modular. Se uma loja precisar adicionar outra dependência, ela deve fazer isso e o mais explicitamente possível . Aqui está um pouco desse código Flux novamente:
PromosStore.dispatchToken = dispatcher.register(payload => { if (payload.actionType === 'add-to-cart') { // wait for CartStore to update first: dispatcher.waitFor([CartStore.dispatchToken]) // now send the request sendPromosRequest(UserStore.userId, CartStore.items).then(promos => { dispatcher.dispatch({ actionType: 'promos-fetched', promos }) }) } if (payload.actionType === 'promos-fetched') { PromosStore.setPromos(payload.promos) } })
PromosStore tem múltiplas dependências declaradas de maneiras diferentes - ele espera e lê de CartStore e lê de UserStore . A única maneira de descobrir essas dependências é procurar lojas na implementação do PromosStore.
Ao contrário dos heróis desta história:
Os heróis
Em 2020, entrou em cena tropeçando. Embora um pouco desajeitado no início, ele nos ensinou um novo padrão que reviveu a abordagem de várias lojas do Flux.
// a Recoil atom const greetingAtom = atom({ key: 'greeting', default: 'Hello, World!', })
// a Jotai atom const greetingAtom = atom('Hello, World!')
// a (better?) Jotai atom const greetingAtom = atom('Hello, World!') greetingAtom.debugLabel = 'greeting'
A curva de aprendizado. Os átomos são diferentes . Como tornamos esses conceitos acessíveis para os desenvolvedores do React?
- Dev X e depuração. Como tornamos os átomos detectáveis? Como você rastreia atualizações ou aplica boas práticas?
- Migração incremental para bases de código existentes. Como você acessa as lojas externas? Como você mantém a lógica existente intacta? Como você evita uma reescrita completa?
Plug-ins. Como tornamos o modelo atômico extensível? Ele pode lidar com todas as situações possíveis?
- Injeção de dependência. Os átomos definem naturalmente as dependências, mas eles podem ser trocados durante o teste ou em ambientes diferentes?
- A Lei de Deméter. Como ocultamos detalhes de implementação e evitamos atualizações dispersas?
Zedux
Zedux finalmente entrou em cena há algumas semanas. Desenvolvido por uma empresa Fintech em Nova York - a empresa para a qual trabalho - o Zedux não foi projetado apenas para ser rápido e escalável, mas também para fornecer uma experiência elegante de desenvolvimento e depuração.
// a Zedux atom const greetingAtom = atom('greeting', 'Hello, World!')
Então, o que exatamente é o modelo atômico?
O modelo atômico
Essas bibliotecas atômicas têm muitas diferenças - elas até têm definições diferentes do que significa "atômico". O consenso geral é que os átomos são contêineres de estado autônomos, pequenos e isolados, atualizados de forma reativa por meio de um gráfico acíclico direcionado.
- Autonomia - Os átomos podem ser testados e usados completamente de forma isolada.
- Divisão de código - Importe um átomo e use-o! Nenhuma consideração extra necessária.
- Primitivos padronizados - Qualquer coisa pode expor um átomo para integração automática.
- Escalabilidade - As atualizações afetam apenas uma pequena parte da árvore de estado.
- Destruição - Basta parar de usar um átomo e todo o seu estado é coletado como lixo.
- Colocation - Os átomos definem naturalmente seu próprio estado, efeitos colaterais e lógica de atualização.
As APIs simples e a escalabilidade por si só tornam as bibliotecas atômicas uma excelente escolha para todos os aplicativos React. Mais potência e menos clichê do que o Redux? Isso é um sonho?
Conclusão
Que jornada! O mundo do gerenciamento de estado do React nunca para de surpreender, e estou muito feliz por ter pegado carona.
Este artigo é o segundo de uma série de recursos de aprendizado que estou produzindo para ajudar os desenvolvedores do React a entender como as bibliotecas atômicas funcionam e por que você pode querer usar uma. Confira o primeiro artigo - Scalability: the Lost Level of React State Management .
L O A D I N G
. . . comments & more!
. . . comments & more!



