





























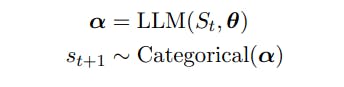










visit
Efficient Guided Generation for Large Language Models: LLM Sampling and Guided Generation by@textmodels
206 reads
Efficient Guided Generation for Large Language Models: LLM Sampling and Guided Generation
by Writings, Papers and Blogs on Text ModelsJune 2nd, 2024
Too Long; Didn't Read
Researchers propose a finite-state machine framework for text generation, offering precise control and improved performance.Author:
(1) Brandon T. Willard, Normal Computing; (2) R´emi Louf, Normal Computing.Table of Links
- Abstract and Intro
- LLM Sampling and Guided Generation
- Iterative FSM Processing and Indexing
- Extensions to Iterative Parsing
- Discussion, References and Acknowledgments
2. LLM Sampling and Guided Generation
Let St = (s1 . . . st) represent a sequence of t tokens with st ∈ V, V a vocabulary, and |V| = N. The vocabularies, V, are composed of strings from a fixed alphabet [Sennrich et al., 2015] and N is often on the order of 104 or larger.
2.1 Sampling sequences
Let F ⊂ P (V), where P is the powerset operator, be subsets of multi-token strings that end with a special token EOS ∈ V. The text generation task is to draw samples from F.
2.2 Guiding generation
This paper is under CC 4.0 license.
L O A D I N G
. . . comments & more!
. . . comments & more!







