





























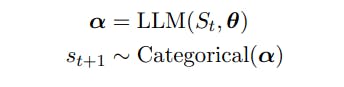













Jan 01, 1970
বড় ভাষার মডেলের জন্য দক্ষ নির্দেশিত প্রজন্ম: এলএলএম স্যাম্পলিং এবং গাইডেড জেনারেশন দ্বারা@textmodels
206 পড়া
বড় ভাষার মডেলের জন্য দক্ষ নির্দেশিত প্রজন্ম: এলএলএম স্যাম্পলিং এবং গাইডেড জেনারেশন
দ্বারা Writings, Papers and Blogs on Text Models2m2024/06/02
অতিদীর্ঘ; পড়তে
গবেষকরা টেক্সট জেনারেশনের জন্য একটি সসীম-স্টেট মেশিন ফ্রেমওয়ার্ক প্রস্তাব করেন, যা সুনির্দিষ্ট নিয়ন্ত্রণ এবং উন্নত কর্মক্ষমতা প্রদান করে।লেখক:
(1) ব্র্যান্ডন টি. উইলার্ড, নরমাল কম্পিউটিং; (2) রেমি লাউফ, সাধারণ কম্পিউটিং।লিঙ্কের টেবিল
- বিমূর্ত এবং ভূমিকা
- এলএলএম স্যাম্পলিং এবং গাইডেড জেনারেশন
- পুনরাবৃত্তিমূলক FSM প্রক্রিয়াকরণ এবং সূচীকরণ
- পুনরাবৃত্তিমূলক পার্সিংয়ের এক্সটেনশন
- আলোচনা, রেফারেন্স এবং স্বীকৃতি
2. এলএলএম স্যাম্পলিং এবং গাইডেড জেনারেশন
আসুন St = (s1 ... st) st ∈ V, V a শব্দভাণ্ডার এবং |V| সহ t টোকেনের একটি ক্রম উপস্থাপন করুন = N. শব্দভান্ডার, V, একটি নির্দিষ্ট বর্ণমালা [Sennrich et al., 2015] থেকে স্ট্রিং দিয়ে গঠিত এবং N প্রায়ই 104 বা তার চেয়ে বড় হয়।
2.1 স্যাম্পলিং সিকোয়েন্স
ধরুন F ⊂ P (V), যেখানে P হল পাওয়ারসেট অপারেটর, মাল্টি-টোকেন স্ট্রিংগুলির উপসেট যা একটি বিশেষ টোকেন EOS ∈ V দিয়ে শেষ হয়৷ পাঠ্য তৈরির কাজটি হল F থেকে নমুনা আঁকা৷
2.2 পথপ্রদর্শক প্রজন্ম
এই কাগজটি CC 4.0 লাইসেন্সের অধীনে ।
L O A D I N G
. . . comments & more!
. . . comments & more!



