





























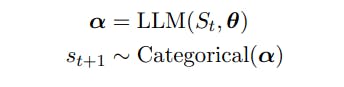













Jan 01, 1970
Büyük Dil Modelleri için Verimli Kılavuzlu Oluşturma: LLM Örnekleme ve Kılavuzlu Oluşturma ile@textmodels
206 okumalar
Büyük Dil Modelleri için Verimli Kılavuzlu Oluşturma: LLM Örnekleme ve Kılavuzlu Oluşturma
ile Writings, Papers and Blogs on Text Models2m2024/06/02
Çok uzun; Okumak
Araştırmacılar, metin üretimi için hassas kontrol ve gelişmiş performans sunan sonlu durumlu bir makine çerçevesi öneriyor.Yazar:
(1) Brandon T. Willard, Normal Hesaplama; (2) R'emi Louf, Normal Hesaplama.Bağlantı Tablosu
- Özet ve Giriş
- LLM Örnekleme ve Kılavuzlu Üretim
- Yinelemeli FSM İşleme ve İndeksleme
- Yinelemeli Ayrıştırma Uzantıları
- Tartışma, Referanslar ve Teşekkür
2. LLM Örnekleme ve Kılavuzlu Üretim
St = (s1 . . . st), st ∈ V, V'nin sözcük dağarcığı ve |V| ile bir t jeton dizisini temsil etmesine izin verin. = N. Kelime dağarcığı, V, sabit bir alfabeden gelen dizilerden oluşur [Sennrich ve diğerleri, 2015] ve N genellikle 104 veya daha büyük mertebesindedir.
2.1 Örnekleme dizileri
P'nin güç kümesi operatörü olduğu F ⊂ P (V), özel bir belirteç EOS ∈ V ile biten çoklu belirteçli dizelerin alt kümeleri olsun. Metin oluşturma görevi, F'den örnekler çekmektir.
2.2 Rehber oluşturma
Bu makale .
L O A D I N G
. . . comments & more!
. . . comments & more!



