





























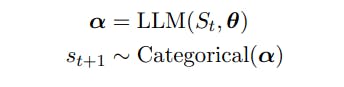













Jan 01, 1970
Generación guiada eficiente para modelos de lenguaje grandes: muestreo de LLM y generación guiada por@textmodels
206 lecturas
Generación guiada eficiente para modelos de lenguaje grandes: muestreo de LLM y generación guiada
por Writings, Papers and Blogs on Text Models2m2024/06/02
Demasiado Largo; Para Leer
Los investigadores proponen un marco de máquina de estados finitos para la generación de texto, que ofrece un control preciso y un rendimiento mejorado.Autor:
(1) Brandon T. Willard, Computación normal; (2) R´emi Louf, Computación Normal.Tabla de enlaces
- Resumen e introducción
- Muestreo LLM y generación guiada
- Procesamiento e indexación iterativos de FSM
- Extensiones al análisis iterativo
- Discusión, referencias y agradecimientos
2. Muestreo LLM y generación guiada
Sea St = (s1 . . . st) representar una secuencia de t tokens con st ∈ V, V un vocabulario y |V| = N. Los vocabularios, V, se componen de cadenas de un alfabeto fijo [Sennrich et al., 2015] y N suele ser del orden de 104 o más.
2.1 Secuencias de muestreo
Sean F ⊂ P (V), donde P es el operador de conjunto de potencias, subconjuntos de cadenas de múltiples tokens que terminan con un token especial EOS ∈ V. La tarea de generación de texto es extraer muestras de F.
2.2 Generación de guía
Este documento está bajo licencia CC 4.0.
L O A D I N G
. . . comments & more!
. . . comments & more!



