







































Jan 01, 1970
মিক্সট্রাল একাধিক বেঞ্চমার্ক জুড়ে লামা এবং GPT-3.5কে ছাড়িয়ে যায় দ্বারা@textmodels
নতুন ইতিহাস
মিক্সট্রাল একাধিক বেঞ্চমার্ক জুড়ে লামা এবং GPT-3.5কে ছাড়িয়ে যায়
দ্বারা Writings, Papers and Blogs on Text Models4m2024/10/18
অতিদীর্ঘ; পড়তে
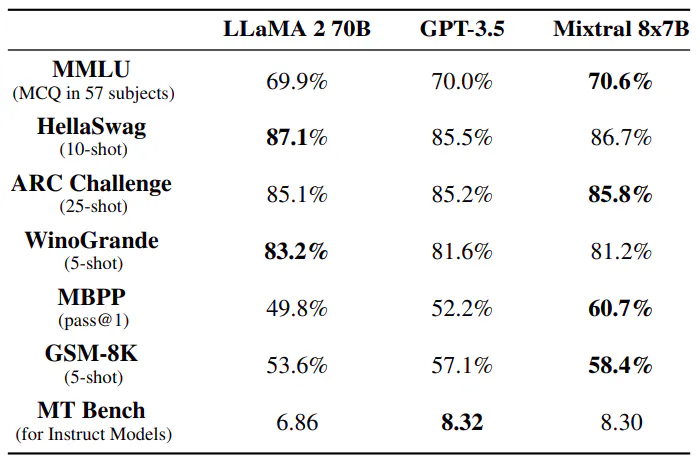
Mixtral 8x7B কমনসেন্স যুক্তি, গণিত এবং কোড জেনারেশন সহ অসংখ্য বেঞ্চমার্কে Llama 2 70B এবং GPT-3.5কে ছাড়িয়ে গেছে। শুধুমাত্র 13B সক্রিয় পরামিতিগুলির সাথে, Mixtral তুলনীয় বা উচ্চতর কর্মক্ষমতা অর্জন করে যখন তার সমকক্ষের তুলনায় আরো দক্ষ হয়। 47B প্যারামিটারের ছোট ক্ষমতা থাকা সত্ত্বেও, Mixtral MMLU-এর মতো মেট্রিক্সে উৎকর্ষ সাধন করে এবং বিভিন্ন কাজ জুড়ে দৃঢ় কর্মক্ষমতা প্রদর্শন করে, এটি ভাষা মডেলিং অ্যাপ্লিকেশনের জন্য একটি শক্তিশালী পছন্দ করে তোলে।লিঙ্কের টেবিল
2 আর্কিটেকচারাল বিশদ এবং 2.1 বিশেষজ্ঞদের স্পার্স মিশ্রণ
3.1 বহুভাষিক বেঞ্চমার্ক, 3.2 দীর্ঘ পরিসরের কর্মক্ষমতা, এবং 3.3 বায়াস বেঞ্চমার্ক
6 উপসংহার, স্বীকৃতি, এবং রেফারেন্স
3 ফলাফল
আমরা মিক্সট্রালকে লামার সাথে তুলনা করি এবং ন্যায্য তুলনা করার জন্য আমাদের নিজস্ব মূল্যায়ন পাইপলাইনের সাথে সমস্ত মানদণ্ড পুনরায় চালাই। আমরা নিম্নলিখিত হিসাবে শ্রেণীবদ্ধ করা বিভিন্ন কাজের উপর কর্মক্ষমতা পরিমাপ করি:
• কমনসেন্স রিজনিং (0-শট): হেলাসওয়াগ [৩২], উইনোগ্রান্ডে [২৬], পিআইকিউএ [৩], এসআইকিউএ [২৭], ওপেনবুককিউএ [২২], এআরসি-ইজি, এআরসি-চ্যালেঞ্জ [৮], কমনসেন্সকিউএ [৩০]
• বিশ্ব জ্ঞান (5-শট): প্রাকৃতিক প্রশ্ন [20], ট্রিভিয়াকিউএ [19]
• রিডিং কম্প্রিহেনশন (0-শট): BoolQ [7], QuAC [5]
• গণিত: GSM8K [9] (8-শট) maj@8 সহ এবং MATH [17] (4-শট) maj@4 সহ
• কোড: মানবিক [4] (0-শট) এবং MBPP [1] (3-শট)
• জনপ্রিয় সমষ্টিগত ফলাফল: MMLU [16] (5-শট), BBH [29] (3-শট), এবং AGI ইভাল [34] (3-5-শট, শুধুমাত্র ইংরেজি একাধিক-পছন্দের প্রশ্ন)
আকার এবং দক্ষতা। আমরা আমাদের পারফরম্যান্সকে লামা 2 পরিবারের সাথে তুলনা করি, খরচ-পারফরম্যান্স বর্ণালীতে মিক্সট্রাল মডেলের দক্ষতা বোঝার লক্ষ্যে (চিত্র 3 দেখুন)। বিক্ষিপ্ত মিশ্রণের-বিশেষজ্ঞ মডেল হিসাবে, Mixtral প্রতিটি টোকেনের জন্য শুধুমাত্র 13B সক্রিয় প্যারামিটার ব্যবহার করে। 5x কম সক্রিয় প্যারামিটার সহ, Mixtral বেশিরভাগ বিভাগে Llama 2 70B কে ছাড়িয়ে যেতে সক্ষম।
মূল্যায়ন পার্থক্য. কিছু বেঞ্চমার্কে, আমাদের মূল্যায়ন প্রোটোকল এবং Llama 2 পেপারে রিপোর্ট করা একটির মধ্যে কিছু পার্থক্য রয়েছে: 1) MBPP-তে, আমরা হাতে-যাচাই করা উপসেট ব্যবহার করি 2) TriviaQA-তে, আমরা উইকিপিডিয়া প্রসঙ্গ সরবরাহ করি না।
এই কাগজটি CC 4.0 লাইসেন্সের অধীনে ।
[২] যেহেতু Llama 2 34B ওপেন সোর্সড ছিল না, তাই আমরা Llama 1 34B-এর ফলাফল রিপোর্ট করি।
লেখক:
(1) আলবার্ট কিউ জিয়াং; (2) আলেকজান্ডার সাব্লেরোলস; (3) অ্যান্টোইন রাউক্স; (4) আর্থার মেনশ; (5) Blanche Savary; (6) ক্রিস ব্যামফোর্ড; (৭) দেবেন্দ্র সিং চ্যাপলট; (8) দিয়েগো দে লাস কাসাস; (9) এমা বো হান্না; (10) ফ্লোরিয়ান ব্রেস্যান্ড; (11) জিয়ানা লেঙ্গেল; (12) Guillaume Bour; (13) Guillaume Lample; (14) Lélio Renard Lavaud; (15) Lucile Saulnier; (16) মারি-অ্যান ল্যাচক্স; (17) পিয়েরে স্টক; (18) সন্দীপ সুব্রামানিয়ান; (19) সোফিয়া ইয়াং; (20) Szymon Antoniak; (21) তেভেন লে স্কাও; (22) থিওফাইল গারভেট; (23) Thibaut Lavril; (24) টমাস ওয়াং; (25) টিমোথি ল্যাক্রোইক্স; (26) উইলিয়াম এল সাইদ।
L O A D I N G
. . . comments & more!
. . . comments & more!



