







































Jan 01, 1970
Mixtral supera a Llama y GPT-3.5 en múltiples indicadores por@textmodels
Nueva Historia
Mixtral supera a Llama y GPT-3.5 en múltiples indicadores
por Writings, Papers and Blogs on Text Models4m2024/10/18
Demasiado Largo; Para Leer
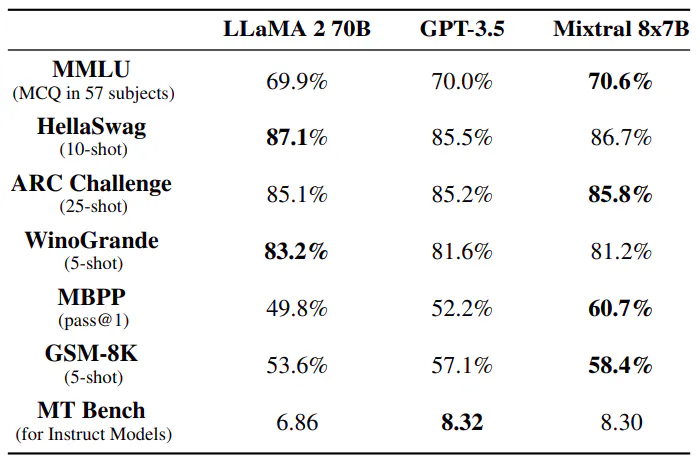
Mixtral 8x7B supera a Llama 2 70B y GPT-3.5 en numerosos puntos de referencia, incluidos razonamiento de sentido común, matemáticas y generación de código. Con solo 13 000 millones de parámetros activos, Mixtral logra un rendimiento comparable o superior y, al mismo tiempo, es más eficiente que sus contrapartes. A pesar de su menor capacidad de 47 000 millones de parámetros, Mixtral se destaca en métricas como MMLU y demuestra un sólido rendimiento en una variedad de tareas, lo que lo convierte en una opción sólida para aplicaciones de modelado de lenguaje.Tabla de enlaces
2 Detalles arquitectónicos y 2.1 Mezcla dispersa de expertos
4 Ajuste fino de instrucciones
6 Conclusión, agradecimientos y referencias
3 resultados
Comparamos Mixtral con Llama y volvemos a ejecutar todos los puntos de referencia con nuestro propio proceso de evaluación para lograr una comparación justa. Medimos el rendimiento en una amplia variedad de tareas categorizadas de la siguiente manera:
• Razonamiento de sentido común (0-shot): Hellaswag [32], Winogrande [26], PIQA [3], SIQA [27], OpenbookQA [22], ARC-Easy, ARC-Challenge [8], CommonsenseQA [30]
• Conocimiento del mundo (5 disparos): NaturalQuestions [20], TriviaQA [19]
• Comprensión lectora (0-shot): BoolQ [7], QuAC [5]
• Matemáticas: GSM8K [9] (8 disparos) con maj@8 y MATH [17] (4 disparos) con maj@4
• Código: Humaneval [4] (0 disparos) y MBPP [1] (3 disparos)
• Resultados agregados populares: MMLU [16] (5 disparos), BBH [29] (3 disparos) y AGI Eval [34] (3-5 disparos, solo preguntas de opción múltiple en inglés)
Tamaño y eficiencia. Comparamos nuestro desempeño con la familia Llama 2, con el objetivo de comprender la eficiencia de los modelos Mixtral en el espectro costo-rendimiento (ver Figura 3). Como modelo Mixtureof-Experts disperso, Mixtral solo usa 13 mil millones de parámetros activos para cada token. Con parámetros activos 5 veces más bajos, Mixtral puede superar a Llama 2 por 70 mil millones en la mayoría de las categorías.
Diferencias de evaluación. En algunos puntos de referencia, existen algunas diferencias entre nuestro protocolo de evaluación y el informado en el artículo de Llama 2: 1) en MBPP, utilizamos el subconjunto verificado manualmente 2) en TriviaQA, no proporcionamos contextos de Wikipedia.
Este artículo está bajo licencia CC 4.0.
[2] Dado que Llama 2 34B no era de código abierto, informamos los resultados para Llama 1 34B.
Autores:
(1) Albert Q. Jiang; (2) Alexandre Sablayrolles; (3) Antoine Roux; (4) Arturo Mensch; (5) Blanca Savary; (6) Chris Bamford; (7) Devendra Singh Chaplot; (8) Diego de las Casas; (9) Emma Bou Hanna; (10) Florián Bressand; (11) Gianna Lengyel; (12) Guillermo Bour; (13) Guillermo Lample; (14) Lélio Renard Lavaud; (15) Lucile Saulnier; (16) María Ana Lachaux; (17) Pedro Stock; (18) Sandeep Subramanian; (19) Sofía Yang; (20) Simón Antoniak; (21) Teven Le Scao; (22) Théophile Gervet; (23) Thibaut Lavril; (24) Thomas Wang; (25) Timothée Lacroix; (26) William El Sayed.
L O A D I N G
. . . comments & more!
. . . comments & more!



