




Mixtral tejkalon Llama dhe GPT-3.5 në shumë standarde nga@textmodels

Histori e re
Mixtral tejkalon Llama dhe GPT-3.5 në shumë standarde
nga Writings, Papers and Blogs on Text Models4m2024/10/18



















Shume gjate; Te lexosh
Mixtral 8x7B tejkalon Llama 2 70B dhe GPT-3.5 në standarde të shumta, duke përfshirë arsyetimin e zakonshëm, matematikën dhe gjenerimin e kodit. Me vetëm 13B parametra aktivë, Mixtral arrin performancë të krahasueshme ose superiore ndërkohë që është më efikas se homologët e tij. Pavarësisht kapacitetit të tij më të vogël prej 47 B parametrash, Mixtral shkëlqen në metrikë si MMLU dhe demonstron performancë të fortë në një sërë detyrash, duke e bërë atë një zgjedhje të fortë për aplikacionet e modelimit të gjuhës.



Tabela e lidhjeve
2 Detaje arkitekturore dhe 2.1 Përzierje e rrallë e ekspertëve
3.1 Standardet shumëgjuhëshe, 3.2 Performanca me rreze të gjatë dhe 3.3 Paragjykimet
6 Përfundime, Mirënjohje dhe Referenca
3 Rezultate
Ne e krahasojmë Mixtral me Llama dhe i rishikojmë të gjitha standardet me linjën tonë të vlerësimit për krahasim të drejtë. Ne matim performancën në një shumëllojshmëri të gjerë detyrash të kategorizuara si më poshtë:
• Arsyetimi Commonsense (0-shot): Hellaswag [32], Winogrande [26], PIQA [3], SIQA [27], OpenbookQA [22], ARC-Easy, ARC-Sfida [8], CommonsenseQA [30]
• Njohuri Botërore (5-shot): Natyrore Pyetje [20], TriviaQA [19]
• Kuptimi i leximit (0-shot): BoolQ [7], QuAC [5]
• Matematikë: GSM8K [9] (8-shot) me maj@8 dhe MATH [17] (4-shot) me maj@4
• Kodi: Humaneval [4] (0-shot) dhe MBPP [1] (3-shot)
• Rezultatet e grumbulluara të njohura: MMLU [16] (5 goditje), BBH [29] (3 goditje) dhe AGI Eval [34] (3-5 pikë, vetëm pyetje në anglisht me zgjedhje të shumëfishta)





Madhësia dhe efikasiteti. Ne e krahasojmë performancën tonë me familjen Llama 2, duke synuar të kuptojmë efikasitetin e modeleve Mixtral në spektrin e performancës së kostos (shih Figurën 3). Si një model i rrallë Mixtureof-Experts, Mixtral përdor vetëm 13B parametra aktivë për çdo shenjë. Me parametra aktivë 5 herë më të ulët, Mixtral është në gjendje të tejkalojë Llama 2 70B në shumicën e kategorive.

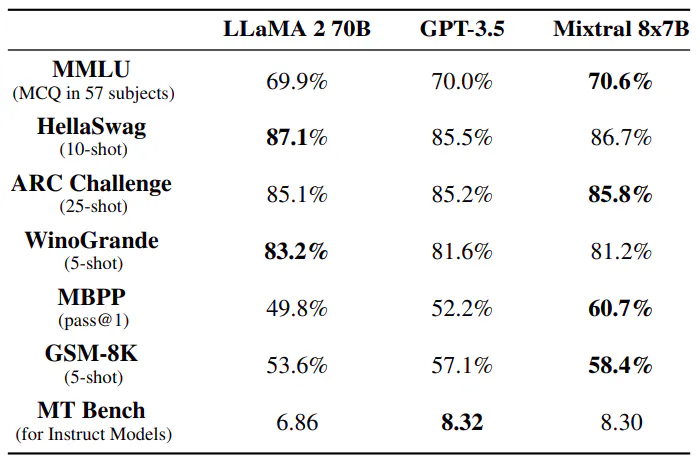
Dallimet në vlerësim. Në disa standarde, ka disa dallime midis protokollit tonë të vlerësimit dhe atij të raportuar në punimin Llama 2: 1) në MBPP, ne përdorim nëngrupin e verifikuar me dorë 2) në TriviaQA, nuk ofrojmë kontekste të Wikipedia-s.
Ky dokument është nën licencën CC 4.0.
[2] Meqenëse Llama 2 34B nuk ishte me burim të hapur, ne raportojmë rezultatet për Llama 1 34B.
Autorët:
(1) Albert Q. Jiang; (2) Alexandre Sablayrolles; (3) Antoine Roux; (4) Arthur Mensch; (5) Blanche Savary; (6) Chris Bamford; (7) Devendra Singh Chaplot; (8) Diego de las Casas; (9) Emma Bou Hanna; (10) Florian Bressand; (11) Gianna Lengyel; (12) Guillaume Bour; (13) Guillaume Lample; (14) Lélio Renard Lavaud; (15) Lucile Saulnier; (16) Marie-Anne Lachaux; (17) Pierre Stock; (18) Sandeep Subramanian; (19) Sophia Yang; (20) Szymon Antoniak; (21) Teven Le Scao; (22) Theophile Gervet; (23) Thibaut Lavril; (24) Thomas Wang; (25) Timothée Lacroix; (26) William El Sayed.
L O A D I N G
. . . comments & more!
. . . comments & more!




