




Mixtral překonává Llama a GPT-3.5 ve více benchmarkech podle@textmodels

Nová historie
Mixtral překonává Llama a GPT-3.5 ve více benchmarkech
podle Writings, Papers and Blogs on Text Models4m2024/10/18



















Příliš dlouho; Číst
Mixtral 8x7B překonává Llama 2 70B a GPT-3.5 v mnoha benchmarcích, včetně logického uvažování, matematiky a generování kódu. S pouhými 13B aktivními parametry dosahuje Mixtral srovnatelného nebo vynikajícího výkonu a zároveň je efektivnější než jeho protějšky. Navzdory své menší kapacitě 47B parametrů vyniká Mixtral v metrikách jako MMLU a prokazuje silný výkon v celé řadě úloh, což z něj činí robustní volbu pro aplikace jazykového modelování.



Tabulka odkazů
2 Architektonické detaily a 2.1 Řídká směs odborníků
3.1 Multilingual benchmarks, 3.2 Long range performance, and 3.3 Bias Benchmarks
3 Výsledky
Porovnáváme Mixtral s Llamou a znovu spouštíme všechny benchmarky s naším vlastním hodnotícím kanálem pro spravedlivé srovnání. Měříme výkon u široké řady úkolů rozdělených do následujících kategorií:
• Commonsense Reasoning (0 snímků): Hellaswag [32], Winogrande [26], PIQA [3], SIQA [27], OpenbookQA [22], ARC-Easy, ARC-Challenge [8], CommonsenseQA [30]
• World Knowledge (5 snímků): NaturalQuestions [20], TriviaQA [19]
• Čtení s porozuměním (0 snímků): BoolQ [7], QuAC [5]
• Matematika: GSM8K [9] (8 snímků) s maj@8 a MATH [17] (4 snímky) s maj@4
• Kód: Humaneval [4] (0 snímků) a MBPP [1] (3 snímky)
• Oblíbené agregované výsledky: MMLU [16] (5 snímků), BBH [29] (3 snímky) a AGI Eval [34] (3–5 snímků, pouze anglické otázky s výběrem z více odpovědí)





Velikost a účinnost. Porovnáváme náš výkon s řadou Llama 2, abychom porozuměli účinnosti modelů Mixtral ve spektru nákladů a výkonu (viz obrázek 3). Jako řídký model Mixtureof-Experts používá Mixtral pouze 13B aktivních parametrů pro každý token. S 5x nižšími aktivními parametry je Mixtral schopen překonat Llama 2 70B napříč většinou kategorií.

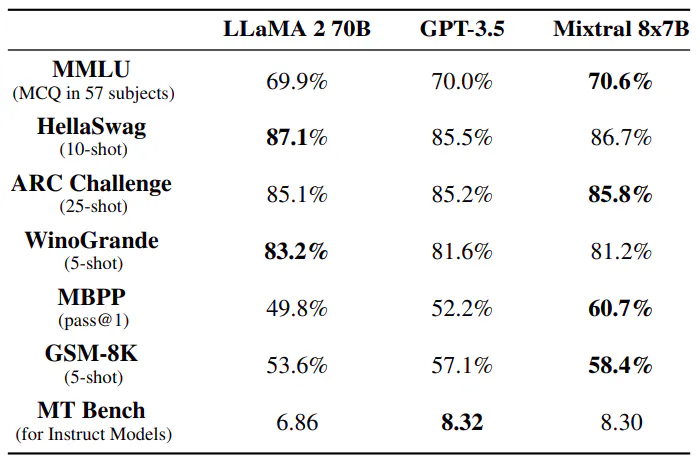
Rozdíly v hodnocení. U některých benchmarků existují určité rozdíly mezi naším vyhodnocovacím protokolem a protokolem uvedeným v článku Llama 2: 1) na MBPP, používáme ručně ověřenou podmnožinu 2) na TriviaQA, neposkytujeme kontexty Wikipedie.
Tento dokument je pod licencí CC 4.0.
[2] Protože Llama 2 34B nebyla open-source, uvádíme výsledky pro Llama 1 34B.
autoři:
(1) Albert Q. Jiang; (2) Alexandre Sablayrolles; (3) Antoine Roux; (4) Arthur Mensch; (5) Blanche Savary; (6) Chris Bamford; (7) Devendra Singh Chaplot; (8) Diego de las Casas; (9) Emma Bou Hanna; (10) Florian Bressand; (11) Gianna Lengyel; (12) Guillaume Bour; (13) Guillaume Lample; (14) Lélio Renard Lavaud; (15) Lucile Saulnier; (16) Marie-Anne Lachaux; (17) Pierre Stock; (18) Sandeep Subramanian; (19) Sophia Yang; (20) Szymon Antoniak; (21) Teven Le Scao; (22) Théophile Gervet; (23) Thibaut Lavril; (24) Thomas Wang; (25) Timothée Lacroix; (26) William El Sayed.
L O A D I N G
. . . comments & more!
. . . comments & more!




