






































Jan 01, 1970
Mixtral overgår Llama og GPT-3.5 på tværs af flere benchmarks ved@textmodels
Ny historie
Mixtral overgår Llama og GPT-3.5 på tværs af flere benchmarks
ved Writings, Papers and Blogs on Text Models4m2024/10/18
For langt; At læse
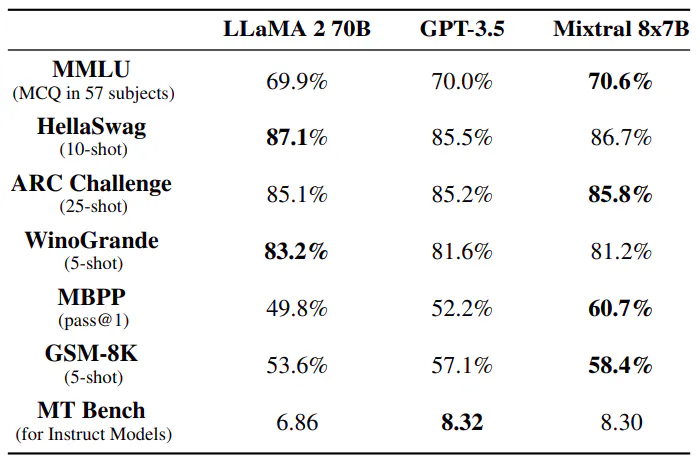
Mixtral 8x7B overgår Llama 2 70B og GPT-3.5 i adskillige benchmarks, herunder sund fornuft, matematik og kodegenerering. Med kun 13B aktive parametre opnår Mixtral sammenlignelig eller overlegen ydeevne, samtidig med at den er mere effektiv end sine modparter. På trods af sin mindre kapacitet på 47B parametre, udmærker Mixtral sig i målinger som MMLU og demonstrerer stærk ydeevne på tværs af en række opgaver, hvilket gør det til et robust valg til sprogmodelleringsapplikationer.Tabel over links
2 Arkitektoniske detaljer og 2.1 Sparsom blanding af eksperter
3.1 Flersprogede benchmarks, 3.2 Lang rækkevidde og 3.3 Bias Benchmarks
6 Konklusion, anerkendelser og referencer
3 resultater
Vi sammenligner Mixtral med Llama, og genkører alle benchmarks med vores egen evalueringspipeline for fair sammenligning. Vi måler ydeevne på en bred vifte af opgaver kategoriseret som følger:
• Commonsense Reasoning (0-shot): Hellaswag [32], Winogrande [26], PIQA [3], SIQA [27], OpenbookQA [22], ARC-Easy, ARC-Challenge [8], CommonsenseQA [30]
• Verdensviden (5-skud): NaturalQuestions [20], TriviaQA [19]
• Læseforståelse (0-shot): BoolQ [7], QuAC [5]
• Matematik: GSM8K [9] (8-skud) med maj@8 og MATH [17] (4-skud) med maj@4
• Kode: Humaneval [4] (0-skud) og MBPP [1] (3-skud)
• Populære samlede resultater: MMLU [16] (5 skud), BBH [29] (3 skud) og AGI Eval [34] (3-5 skud, kun engelske multiple-choice spørgsmål)
Størrelse og effektivitet. Vi sammenligner vores ydeevne med Llama 2-familien med det formål at forstå Mixtral-modellernes effektivitet i spektret af omkostningsydelser (se figur 3). Som en sparsom Mixtureof-Experts-model bruger Mixtral kun 13B aktive parametre for hvert token. Med 5x lavere aktive parametre er Mixtral i stand til at overgå Llama 2 70B på tværs af de fleste kategorier.
Evalueringsforskelle. På nogle benchmarks er der nogle forskelle mellem vores evalueringsprotokol og den, der er rapporteret i Llama 2-papiret: 1) på MBPP bruger vi den håndverificerede delmængde 2) på TriviaQA, vi leverer ikke Wikipedia-kontekster.
Dette papir er under CC 4.0-licens.
[2] Da Llama 2 34B ikke var open source, rapporterer vi resultater for Llama 1 34B.
Forfattere:
(1) Albert Q. Jiang; (2) Alexandre Sablayrolles; (3) Antoine Roux; (4) Arthur Mensch; (5) Blanche Savary; (6) Chris Bamford; (7) Devendra Singh Chaplot; (8) Diego de las Casas; (9) Emma Bou Hanna; (10) Florian Bressand; (11) Gianna Lengyel; (12) Guillaume Bour; (13) Guillaume Lample; (14) Lélio Renard Lavaud; (15) Lucile Saulnier; (16) Marie-Anne Lachaux; (17) Pierre Stock; (18) Sandeep Subramanian; (19) Sophia Yang; (20) Szymon Antoniak; (21) Teven Le Scao; (22) Théophile Gervet; (23) Thibaut Lavril; (24) Thomas Wang; (25) Timothée Lacroix; (26) William El Sayed.
L O A D I N G
. . . comments & more!
. . . comments & more!


