





























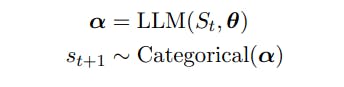













Jan 01, 1970
बड़े भाषा मॉडल के लिए कुशल निर्देशित पीढ़ी: एलएलएम नमूनाकरण और निर्देशित पीढ़ी द्वारा@textmodels
206 रीडिंग
बड़े भाषा मॉडल के लिए कुशल निर्देशित पीढ़ी: एलएलएम नमूनाकरण और निर्देशित पीढ़ी
द्वारा Writings, Papers and Blogs on Text Models2m2024/06/02
बहुत लंबा; पढ़ने के लिए
शोधकर्ताओं ने पाठ निर्माण के लिए एक परिमित-अवस्था मशीन ढांचे का प्रस्ताव दिया है, जो सटीक नियंत्रण और बेहतर प्रदर्शन प्रदान करता है।लेखक:
(1) ब्रैंडन टी. विलार्ड, नॉर्मल कंप्यूटिंग; (2) रेमी लौफ, नॉर्मल कंप्यूटिंग।लिंक की तालिका
- सार और परिचय
- एलएलएम नमूनाकरण और निर्देशित पीढ़ी
- पुनरावृत्तीय एफएसएम प्रसंस्करण और अनुक्रमण
- पुनरावृत्तीय पार्सिंग के लिए विस्तार
- चर्चा, संदर्भ और आभार
2. एलएलएम नमूनाकरण और निर्देशित पीढ़ी
मान लें कि St = (s1 . . . st) t टोकनों के अनुक्रम को दर्शाता है जिसमें st ∈ V है, V एक शब्दावली है, और |V| = N है। शब्दावली, V, एक निश्चित वर्णमाला [सेनरिच एट अल., 2015] से स्ट्रिंग्स से बनी होती है और N अक्सर 104 या उससे बड़ी होती है।
2.1 नमूनाकरण अनुक्रम
मान लें कि F ⊂ P (V), जहाँ P पावरसेट ऑपरेटर है, बहु-टोकन स्ट्रिंग के उपसमुच्चय हैं जो एक विशेष टोकन EOS ∈ V के साथ समाप्त होते हैं। पाठ निर्माण कार्य F से नमूने निकालना है।
2.2 मार्गदर्शक पीढ़ी
यह पेपर CC 4.0 लाइसेंस के अंतर्गत है।
L O A D I N G
. . . comments & more!
. . . comments & more!



