







































Jan 01, 1970
Mixtral は複数のベンチマークで Llama と GPT-3.5 を上回る に@textmodels
新しい歴史
Mixtral は複数のベンチマークで Llama と GPT-3.5 を上回る
に Writings, Papers and Blogs on Text Models4m2024/10/18
長すぎる; 読むには
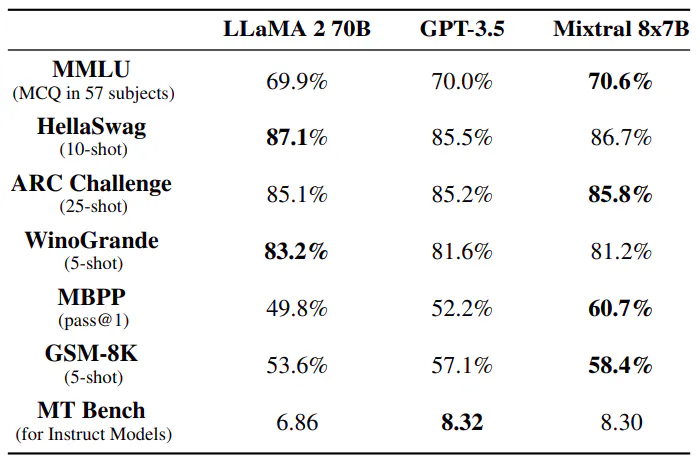
Mixtral 8x7B は、常識的推論、数学、コード生成など、数多くのベンチマークで Llama 2 70B および GPT-3.5 を上回っています。わずか 13B のアクティブ パラメータで、Mixtral は同等以上のパフォーマンスを実現しながら、他の競合製品よりも効率的です。47B パラメータという容量は小さいものの、Mixtral は MMLU などのメトリクスで優れており、さまざまなタスクで強力なパフォーマンスを発揮するため、言語モデリング アプリケーションに最適です。リンク一覧
3.1 多言語ベンチマーク、3.2 長距離パフォーマンス、3.3 バイアスベンチマーク
3 件の結果
Mixtral と Llama を比較し、正义な比較のために独自一人の評価パイプラインですべてのベンチマークを再実行します。次のように分類されるさまざまなタスクでパフォーマンスを測定します。
• Commonsense Reasoning (0-shot): Hellaswag [32]、Winogrande [26]、PIQA [3]、SIQA [27]、OpenbookQA [22]、ARC-Easy、ARC-Challenge [8]、CommonsenseQA [30]
• 世界知識(5回): NaturalQuestions [20]、TriviaQA [19]
• 読解力(0点): BoolQ [7]、QuAC [5]
• 数学: GSM8K [9] (8ショット)、maj@8、MATH [17] (4ショット)、maj@4
• コード:ヒューマニバル [4] (0発) および MBPP [1] (3発)
• 人気の集計結果: MMLU [16] (5回)、BBH [29] (3回)、AGI Eval [34] (3~5回、英語の多肢選択問題のみ)
サイズと効率。コスト パフォーマンス スペクトルにおける Mixtral モデルの効率性を理解するために、パフォーマンスを Llama 2 ファミリーと比較します (図 3 を参照)。Mixtral はスパースな Mixtureof-Experts モデルとして、トークンごとに 130 億のアクティブ パラメータのみを使用します。アクティブ パラメータが 5 分の 1 に抑えられた Mixtral は、ほとんどのカテゴリで Llama 2 700 億を上回るパフォーマンスを発揮します。
評価の違い。一部のベンチマークでは、私たちの評価プロトコルと Llama 2 論文で報告されたものとの間にいくつかの違いがあります。1) MBPP では、手動で検証されたサブセットを使用します。2) TriviaQA では、Wikipedia コンテキストを提供しません。
この論文はCC 4.0ライセンスの下で。
[2] Llama 2 34Bはオープンソース化されていないため、Llama 1 34Bの結果を報告する。
著者:
(1)アルバート・Q・ジャン(2)アレクサンドル・サブレイロール(3)アントワーヌ・ルー(4)アーサー・メンシュ(5)ブランシュ・サヴァリー(6)クリス・バンフォード(7)デヴェンドラ・シン・チャプロット(8)ディエゴ・デ・ラス・カサス(9)エマ・ボウ・ハンナ(10)フロリアン・ブレッサンド(11)ジャンナ・レンゲル(12)ギヨーム・ブール(13)ギヨーム・ランプル(14)レリオ・ルナール・ラヴォー(15)ルシール・ソルニエ(16)マリーアンヌ・ラショー(17)ピエール・ストック(18)サンディープ・スブラマニアン(19)ソフィア・ヤン(20)シモン・アントニアク(21)テヴェン・ル・スカオ(22)テオフィル・ジェルヴェ(23)ティボー・ラヴリル(24)トーマス・ワン(25)ティモシー・ラクロワ(26)ウィリアム・エル・サイード
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
ラベル
関連ストーリー
海を航海する: データレイクを使用した本番環境レベルの RAG アプリケーションの開発
#minio

AI の力を解き放つ。最先端技術の体系的レビュー: 概要と序論 #ai
Jan 01, 1970

クラウド移行を成功させるための完全ガイド: 戦略とベストプラクティス #cloud-migration
Jan 01, 1970

