





























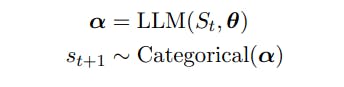













Jan 01, 1970
대규모 언어 모델을 위한 효율적인 안내 생성: LLM 샘플링 및 안내 생성 ~에 의해@textmodels
206 판독값
대규모 언어 모델을 위한 효율적인 안내 생성: LLM 샘플링 및 안내 생성
~에 의해 Writings, Papers and Blogs on Text Models2m2024/06/02
너무 오래; 읽다
연구원들은 정확한 제어와 향상된 성능을 제공하는 텍스트 생성을 위한 유한 상태 기계 프레임워크를 제안합니다.작가:
(1) Brandon T. Willard, 일반 컴퓨팅; (2) R'emi Louf, 일반 컴퓨팅.링크 표
2. LLM 샘플링 및 유도 생성
St = (s1 . . . . st)는 st ∈ V, V는 어휘 및 |V|를 갖는 t 토큰의 시퀀스를 나타냅니다. = N. 어휘 V는 고정된 알파벳의 문자열로 구성되며[Sennrich et al., 2015] N은 종종 104 이상입니다.
2.1 샘플링 순서
P가 거듭제곱 연산자인 F ⊂ P (V)를 특수 토큰 EOS ∈ V로 끝나는 멀티 토큰 문자열의 하위 집합이라고 가정합니다. 텍스트 생성 작업은 F에서 샘플을 그리는 것입니다.
2.2 세대 안내
이 문서는 CC 4.0 라이선스에 따라 있습니다.
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
태그 걸기
관련 기사

AI의 힘을 발휘하세요. 최첨단 기술의 체계적 검토: 개요 및 소개 #ai
Jan 01, 1970


