





























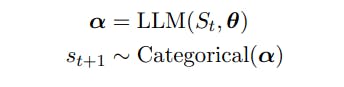













Jan 01, 1970
Geração guiada eficiente para modelos de linguagem grande: amostragem LLM e geração guiada por@textmodels
206 leituras
Geração guiada eficiente para modelos de linguagem grande: amostragem LLM e geração guiada
por Writings, Papers and Blogs on Text Models2m2024/06/02
Muito longo; Para ler
Os pesquisadores propõem uma estrutura de máquina de estados finitos para geração de texto, oferecendo controle preciso e melhor desempenho.Autor:
(1) Brandon T. Willard, Computação Normal; (2) R´emi Louf, Computação Normal.Tabela de links
- Resumo e introdução
- Amostragem LLM e Geração Guiada
- Processamento e indexação iterativo de FSM
- Extensões para análise iterativa
- Discussão, Referências e Agradecimentos
2. Amostragem LLM e Geração Guiada
Seja St = (s1 . . . st) represente uma sequência de t tokens com st ∈ V, V um vocabulário e |V| = N. Os vocabulários, V, são compostos de strings de um alfabeto fixo [Sennrich et al., 2015] e N é frequentemente da ordem de 104 ou maior.
2.1 Sequências de amostragem
Sejam F ⊂ P (V), onde P é o operador powerset, subconjuntos de strings multi-token que terminam com um token especial EOS ∈ V. A tarefa de geração de texto é extrair amostras de F.
2.2 Geração orientadora
Este artigo está sob licença CC 4.0.
L O A D I N G
. . . comments & more!
. . . comments & more!



