







































Jan 01, 1970
Mixtral supera Llama e GPT-3.5 em vários benchmarks por@textmodels
Novo histórico
Mixtral supera Llama e GPT-3.5 em vários benchmarks
por Writings, Papers and Blogs on Text Models4m2024/10/18
Muito longo; Para ler
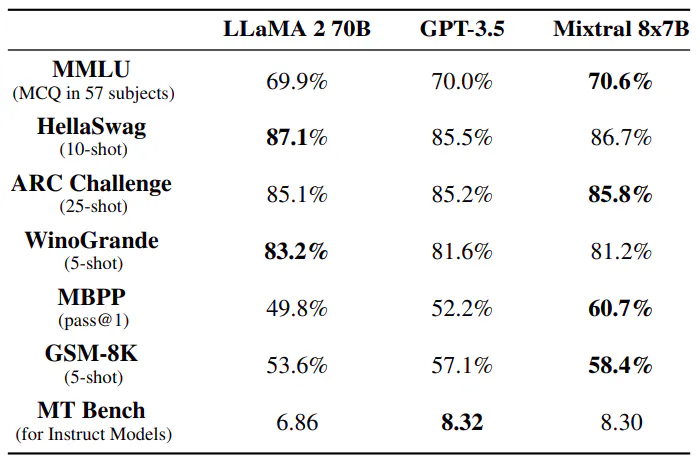
O Mixtral 8x7B supera o Llama 2 70B e o GPT-3.5 em vários benchmarks, incluindo raciocínio de senso comum, matemática e geração de código. Com apenas 13B parâmetros ativos, o Mixtral atinge desempenho comparável ou superior, sendo mais eficiente do que seus equivalentes. Apesar de sua menor capacidade de 47B parâmetros, o Mixtral se destaca em métricas como MMLU e demonstra forte desempenho em uma variedade de tarefas, tornando-o uma escolha robusta para aplicativos de modelagem de linguagem.Tabela de Links
2 Detalhes arquitetônicos e 2.1 Mistura esparsa de especialistas
3.1 Benchmarks multilíngues, 3.2 Desempenho de longo alcance e 3.3 Benchmarks de polarização
6 Conclusão, Agradecimentos e Referências
3 Resultados
Comparamos Mixtral com Llama e reexecutamos todos os benchmarks com nosso próprio pipeline de avaliação para uma comparação justa. Medimos o desempenho em uma ampla variedade de tarefas categorizadas da seguinte forma:
• Raciocínio de senso comum (0-shot): Hellaswag [32], Winogrande [26], PIQA [3], SIQA [27], OpenbookQA [22], ARC-Easy, ARC-Challenge [8], CommonsenseQA [30]
• Conhecimento Mundial (5-shot): NaturalQuestions [20], TriviaQA [19]
• Compreensão de leitura (0-tiro): BoolQ [7], QuAC [5]
• Matemática: GSM8K [9] (8 disparos) com maj@8 e MATH [17] (4 disparos) com maj@4
• Código: Humaneval [4] (0-tiro) e MBPP [1] (3-tiro)
• Resultados agregados populares: MMLU [16] (5-shot), BBH [29] (3-shot) e AGI Eval [34] (3-5-shot, apenas questões de múltipla escolha em inglês)
Tamanho e eficiência. Comparamos nosso desempenho com a família Llama 2, visando entender a eficiência dos modelos Mixtral no espectro de custo-desempenho (veja a Figura 3). Como um modelo esparso Mixtureof-Experts, o Mixtral usa apenas 13B parâmetros ativos para cada token. Com 5x menos parâmetros ativos, o Mixtral é capaz de superar o Llama 2 70B na maioria das categorias.
Diferenças de avaliação. Em alguns benchmarks, há algumas diferenças entre nosso protocolo de avaliação e o relatado no artigo Llama 2: 1) no MBPP, usamos o subconjunto verificado manualmente 2) no TriviaQA, não fornecemos contextos da Wikipedia.
Este artigo está sob licença CC 4.0.
[2] Como o Llama 2 34B não era de código aberto, relatamos os resultados para o Llama 1 34B.
Autores:
(1) Alberto Q. Jiang; (2) Alexandre Sablayrolles; (3) Antônio Roux; (4) Arthur Mensch; (5) Branca Savary; (6) Chris Bamford; (7) Devendra Singh Chaplot; (8) Diego de las Casas; (9) Emma Bou Hanna; (10) Floriano Bressand; (11) Gianna Lengyel; (12) Guilherme Bour; (13) Guilherme Lample; (14) Lélio Renard Lavaud; (15) Lucile Saulnier; (16) Maria Ana Lachaux; (17) Pierre Estoque; (18) Sandeep Subramanian; (19) Sofia Yang; (20) Szymon Antoniak; (21) Dez Le Scao; (22) Teófilo Gervet; (23) Thibaut Lavril; (24) Thomas Wang; (25) Timóteo Lacroix; (26) William El Sayed.
L O A D I N G
. . . comments & more!
. . . comments & more!



