





























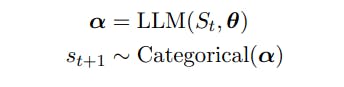













Jan 01, 1970
Эффективная управляемая генерация для больших языковых моделей: выборка LLM и управляемая генерация к@textmodels
206 чтения
Эффективная управляемая генерация для больших языковых моделей: выборка LLM и управляемая генерация
к Writings, Papers and Blogs on Text Models2m2024/06/02
Слишком долго; Читать
Исследователи предлагают структуру конечного автомата для генерации текста, предлагающую точный контроль и повышенную производительность.Автор:
(1) Брэндон Т. Уиллард, Нормальные вычисления; (2) Реми Луф, Нормальные вычисления.Таблица ссылок
- Аннотация и введение
- Выборка LLM и управляемая генерация
- Итеративная обработка и индексирование конечного автомата
- Расширения итеративного анализа
- Обсуждение, ссылки и благодарности
2. Выборка LLM и управляемая генерация
Пусть St = (s1...st) представляет собой последовательность t токенов со st ∈ V, V — словарь и |V| = N. Словари V состоят из строк фиксированного алфавита [Sennrich et al., 2015], а N часто имеет порядок 104 или больше.
2.1 Последовательность отбора проб
Пусть F ⊂ P (V), где P — оператор степенного множества, — это подмножества многосимвольных строк, которые заканчиваются специальным токеном EOS ∈ V. Задача генерации текста состоит в том, чтобы извлечь образцы из F.
2.2 Руководство поколением
Этот документ под лицензией CC 4.0.
L O A D I N G
. . . comments & more!
. . . comments & more!



