







































Jan 01, 1970
Mixtral เหนือกว่า Llama และ GPT-3.5 ในเกณฑ์มาตรฐานต่างๆ โดย@textmodels
ประวัติศาสตร์ใหม่
Mixtral เหนือกว่า Llama และ GPT-3.5 ในเกณฑ์มาตรฐานต่างๆ
โดย Writings, Papers and Blogs on Text Models4m2024/10/18
นานเกินไป; อ่าน
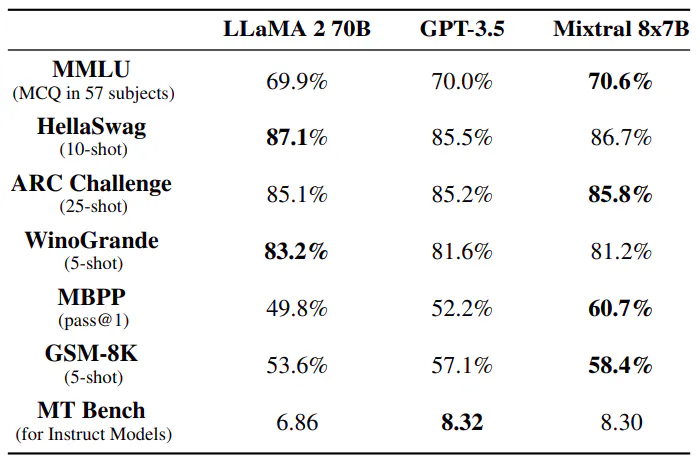
Mixtral 8x7B เหนือกว่า Llama 2 70B และ GPT-3.5 ในเกณฑ์มาตรฐานมากมาย รวมถึงการใช้เหตุผลตามสามัญสำนึก คณิตศาสตร์ และการสร้างโค้ด ด้วยพารามิเตอร์ที่ใช้งานเพียง 13 พันล้านตัว Mixtral จึงให้ประสิทธิภาพที่เทียบเท่าหรือเหนือกว่าในขณะที่มีประสิทธิภาพมากกว่าคู่แข่ง แม้จะมีความจุที่น้อยกว่าคือ 47 พันล้านพารามิเตอร์ แต่ Mixtral ก็โดดเด่นในเมตริกต่างๆ เช่น MMLU และแสดงให้เห็นถึงประสิทธิภาพที่แข็งแกร่งในงานต่างๆ ทำให้เป็นตัวเลือกที่มั่นคงสำหรับแอปพลิเคชันการสร้างแบบจำลองภาษาตารางลิงค์
2 รายละเอียดทางสถาปัตยกรรม และ 2.1 การผสมผสานของผู้เชี่ยวชาญที่เบาบาง
3.1 เกณฑ์มาตรฐานหลายภาษา 3.2 ประสิทธิภาพระยะไกล และ 3.3 เกณฑ์มาตรฐานความลำเอียง
6 บทสรุป คำขอบคุณ และเอกสารอ้างอิง
3 ผลลัพธ์
เราเปรียบเทียบ Mixtral กับ Llama และรันเกณฑ์มาตรฐานทั้งหมดใหม่อีกครั้งโดยใช้ขั้นตอนการประเมินของเราเองเพื่อการเปรียบเทียบที่ยุติธรรม เราวัดประสิทธิภาพในงานที่หลากหลายซึ่งแบ่งประเภทดังนี้:
• การใช้เหตุผลสามัญสำนึก (0 ช็อต): Hellaswag [32], Winogrande [26], PIQA [3], SIQA [27], OpenbookQA [22], ARC-Easy, ARC-Challenge [8], CommonsenseQA [30]
• ความรู้เกี่ยวกับโลก (5 ช็อต): NaturalQuestions [20], TriviaQA [19]
• การอ่านจับใจความ (0-shot): BoolQ [7], QuAC [5]
• คณิตศาสตร์: GSM8K [9] (8-shot) ด้วย maj@8 และ MATH [17] (4-shot) ด้วย maj@4
• รหัส: Humaneval [4] (0 นัด) และ MBPP [1] (3 นัด)
• ผลรวมคะแนนยอดนิยม: MMLU [16] (5 ช็อต), BBH [29] (3 ช็อต) และ AGI Eval [34] (3 ช็อต, คำถามแบบเลือกตอบภาษาอังกฤษเท่านั้น)
ขนาดและประสิทธิภาพ เราเปรียบเทียบประสิทธิภาพของเรากับตระกูล Llama 2 โดยมุ่งหวังที่จะทำความเข้าใจประสิทธิภาพของโมเดล Mixtral ในแง่ของต้นทุน-ประสิทธิภาพ (ดูรูปที่ 3) ในฐานะโมเดล Mixtureof-Experts แบบเบาบาง Mixtral ใช้พารามิเตอร์ที่ใช้งานอยู่เพียง 13 พันล้านตัวสำหรับแต่ละโทเค็น ด้วยพารามิเตอร์ที่ใช้งานอยู่ต่ำกว่า 5 เท่า Mixtral จึงสามารถทำงานได้ดีกว่า Llama 2 70 พันล้านตัวในหมวดหมู่ส่วนใหญ่
ความแตกต่างในการประเมิน ในเกณฑ์มาตรฐานบางรายการ มีความแตกต่างบางประการระหว่างโปรโตคอลการประเมินของเราและโปรโตคอลที่รายงานในเอกสาร Llama 2: 1) ใน MBPP เราใช้ชุดย่อยที่ตรวจยืนยันด้วยมือ 2) ใน TriviaQA เราไม่ได้ให้บริบทของ Wikipedia
เอกสารนี้ ภายใต้ใบอนุญาต CC 4.0
[2] เนื่องจาก Llama 2 34B ไม่ใช่โอเพนซอร์ส เราจึงรายงานผลลัพธ์สำหรับ Llama 1 34B
ผู้แต่ง:
(1) อัลเบิร์ต คิว เจียง; (2) อเล็กซานเดอร์ ซาเบลย์โรลส์; (3) อองตวน รูซ์; (4) อาร์เธอร์ เมนช์; (5) บล็องช์ ซาวารี; (6) คริส แบมฟอร์ด; (7) เทเวนทระ สิงห์ ชาพล็อท; (8) ดิเอโก เดอ ลาส คาซัส; (9) เอ็มม่า บู ฮานน่า; (10) ฟลอเรียน เบรสแซนด์; (11) จิอันน่า เลงเยล; (12) กีโยม บัวร์; (13) กีโยม ลัมเปิล; (14) เลลิโอ เรอนาร์ ลาวอด; (15) ลูซิล ซอลนิเยร์; (16) มารี-แอนน์ ลาโชซ์; (17) ปิแอร์ สต๊อก; (18) สันดีป สุบรามาเนียน; (19) โซเฟีย หยาง; (20) ซิมอน แอนโทเนียก; (21) เทเวน เลอ สเกา; (22) เธโอไฟล์ เฌร์เวต์; (23) ทิโบต์ ลาวริล; (24) โทมัส หว่อง; (25) ทิโมธี ลาครัวซ์; (26) วิลเลียม เอล ซาเยด
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
แขวนแท็ก
เรื่องราวที่เกี่ยวข้อง
The German Air-fleet
#hackernoon-books



